Under-fitting
- train acc. is bad
- test acc. is bad as well
Overfitting
- train loss and acc. is much better
- test acc. is worse
Cross Validation
- train/evaluate/test splitting
- k-fold cross-validation
Train, Val, Test
详见Code
人为划分数据集:
idx = tf.range(60000)
idx = tf.random.shuffle(idx)
x_train, y_train = tf.gather(x, idx[:50000]), tf.gather(y, idx[:50000])
x_val, y_val = tf.gather(x, idx[-10000:]), tf.gather(y, idx[-10000:])
print(x_train.shape, y_train.shape, x_val.shape, y_val.shape)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.map(preprocess).shuffle(50000).batch(batch_size)
db_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_val = db_val.map(preprocess).shuffle(10000).batch(batch_size)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).batch(batch_size)
K-fold Cross Validation
- merge train/val sets
- randomly sample 1/k as val set
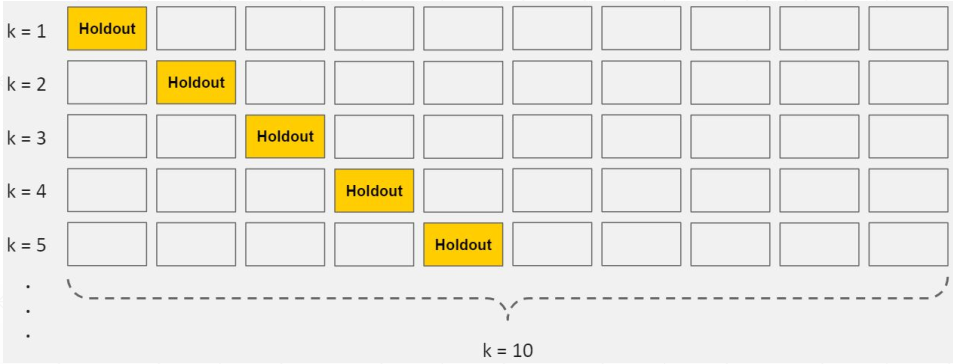
在tensorflow中,设置模型fit训练函数即可实现k-fold交叉验证的效果:
model.fit(db_train_val, epochs=5, validation_split=0.1, validation_freq=2) # 传入的是train和val整个数据集,设置划分比例
Regularization
More things should not be used than are necessary. —Occam’s Razor
Reduce Overfitting
- more data
constraint model complexity
- shallow
- regularization or weight decay
- L1-norm
- L2-norm
# 对权重参数进行正则化操作方式1 loss_regularization = [] for p in network.trainable_variables: loss_regularization.append(tf.nn.l2_loss(p)) loss_regularization = tf.reduce_sum(tf.stack(loss_regularization)) loss = loss + 0.0001 * loss_regularization # 对权重参数进行正则化操作方式2 l2_model = keras.models.Sequential([ keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001), activation=tf.nn.relu, input_shape=input_shape), keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001), activation=tf.nn.relu), keras.layers.Dense(1, activation=tf.nn.sigmoid) ])dropout
data argumentation
early stopping
Learning Rate
Learning rate tunning:
- too low: a small learning rate requires many updates before reaching the minimum point
- just right: the optimal learning rate swiftly reaches the minimum point
- too large of a learning rate causes drastic updates which lead to divergent behaviors
Momentum
在tensorflow中,设置不用优化器的momentum版本很简单,只需要在optimizer中加入momentum参数即可:
optimizer_1 = SGD(learning_rete=0.02, momentum=0.9)
optimizer_2 = RMSprop(learning_rate=0.02, momentum=0.9)
# Adam只需要设置两个beta参数就包含了momentum在内,不需要在指定其他参数
optimizer_3 = Adam(learning_rate=3e-4, beta_1=0.9, beta_2=0.999)
Learning Rate Decay
Adaptive learning rate.
optimizer = SGD(learning_rate=0.2)
for epoch in range(100):
# get loss
# change learning rate
optimizer.learning_rate = 0.2 * (100 - epoch)/100
# update weights
Other Tricks
Early Stopping
- Validation set to select parameters
- Monitor validation performance
- Stop at the highest val perf.
Dropout
详见Code
- Learning less to learn better
- Each connection has $p = [0,1]$ to lose
layer.Dropout(rate) and tf.nn.dropout(x, rate.
需要注意使用dropout之后,在训练和测试时,模型需要传入一个参数,training=True or False
Stochastic Gradient Descent
- Stochastic
- not random!
- not single usually
- batch = 16, 32, 64, 128, …
- Deterministic
Reference
Note: Cover Picture