Terminology & Notation
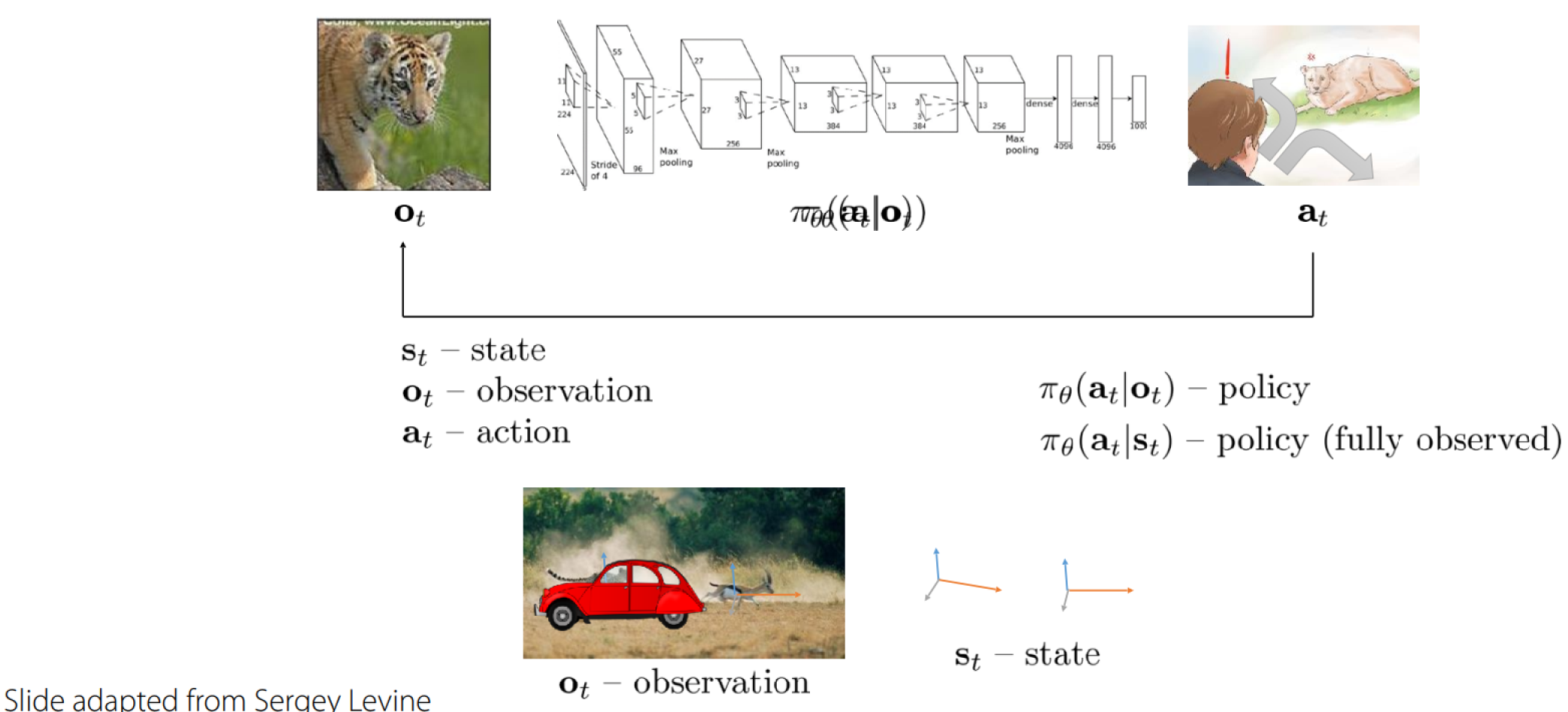
Use the reward function to determine which action is better or worse.
$s, a, r(s,a), p(s\prime|s,a)$ define Markov decision process.
The Goal of Reinforcement Learning
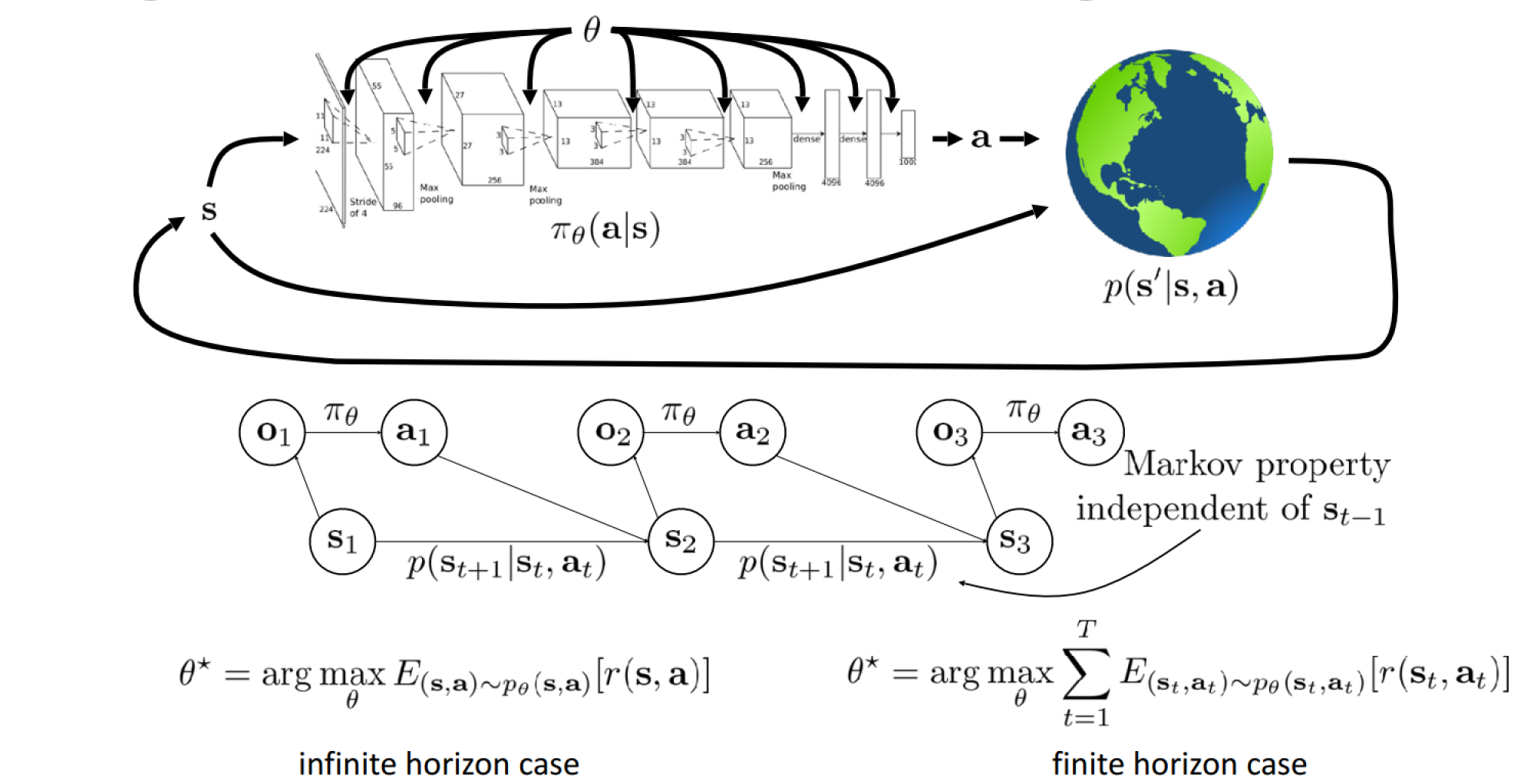
What is a Reinforcement Learning Task

The Goal of Multi-Task Reinforcement Learning
Multi-task RL
The same as before, except a task identifier is part of the state: $s = (\bar{s}, z_i)$, e.g. one-hot task ID, language description, desired goal state, $z_i = s_g$ which is goal-conditioned RL.
The reward is the same as before, or for goal-conditioned RL:
$$ r(s) = r(\bar{s}, s_g) = -d(\bar{s}, s_g) $$
Distance function $d$ examples:
- Euclidean $L_2$
- Sparse 0/1
The Anatomy of a RL Algorithm
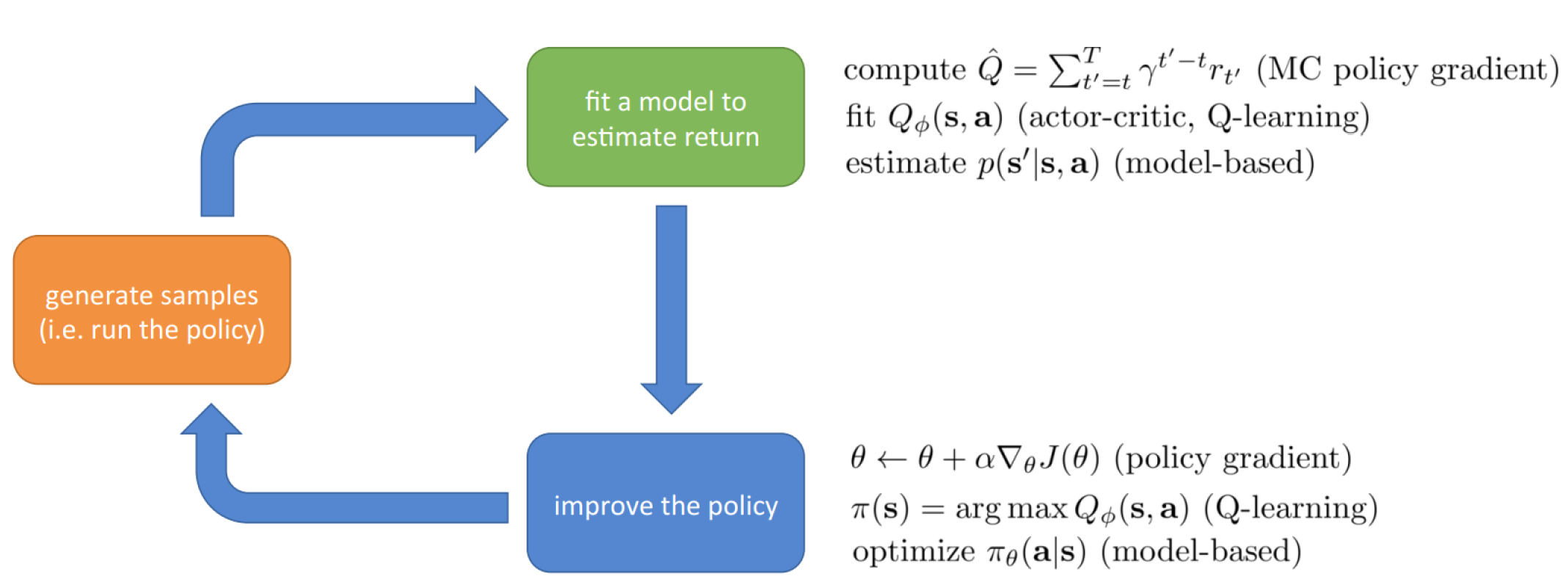
Evaluating the Objective
$$ \theta^* = arg \max_{\theta} J(\theta) $$
Sum over samples from $\pi_\theta$.
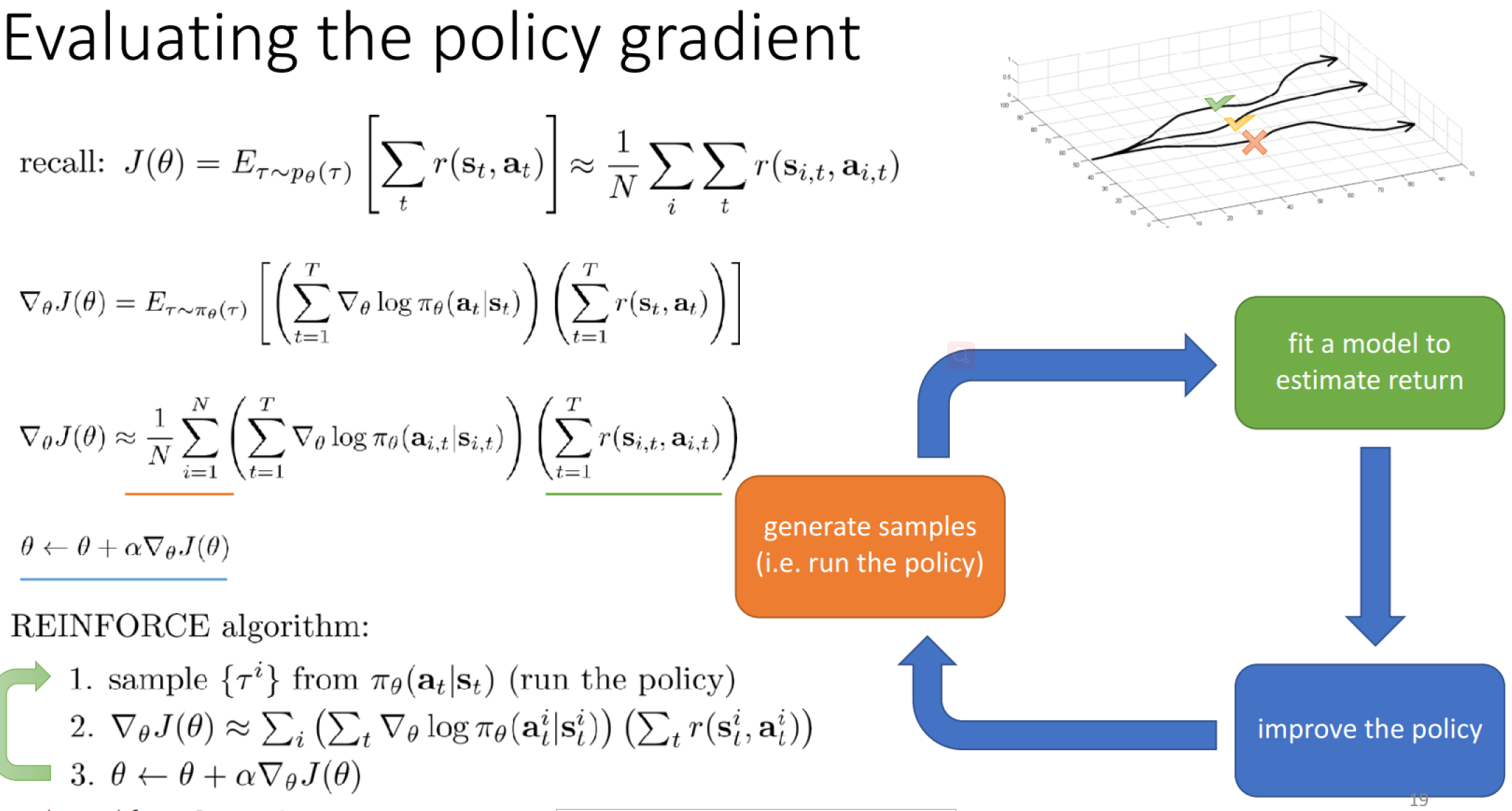
$$ J(\theta) = E_{\tau \sim p_{\theta}(\tau)} \left [ \sum_{t} r(s_t, a_t) \right ] \approx \frac{1}{N} \sum_{i}\sum_{t}r(s_{i,t}, a_{i,t}) $$
Direct Policy Differentiation


Evaluating the Policy Gradient
Comparison to Maximum Likelihood
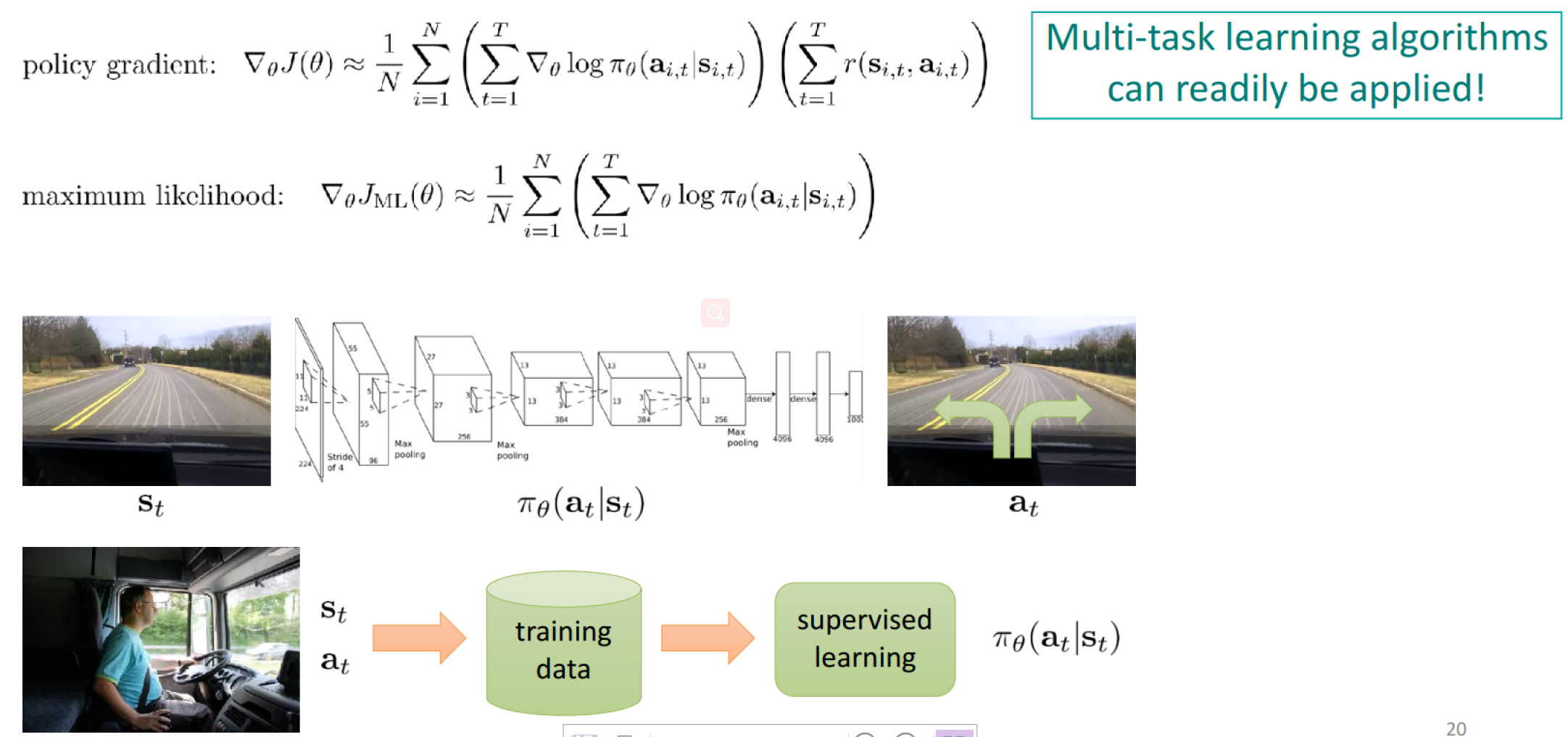
Which means:
- Good stuff is made more likely
- Bad stuff is made less likely
- Simply formalizes the notion of “trail and error”
Summary for Policy Gradients
Pros:
- Simple
- Easy to combine with existing multi-task & meta-learning algorithms.
Cons:
- Produces a high0-variance gradient
- Can be mitigated with baselines (used byu all algorithms in practice), trust regions
- Requires on-policy data
- Cannot reuse existing experience to estimate the gradient
- Importance weights can help, but also high variance
Q-Learning
Value-Based RL: Definitions

For the optimal policy $\pi^*$, it follows the bellman equation:
$$ Q^(s_t, a_t) = E_{s\prime \sim p(\cdot |s,a)} \left [ r(s,a) + \gamma \max_{a\prime} Q^ (s\prime, a\prime) \right ] $$
Fitted Q-iteration Algorithm

Multi-Task Q-Learning
Policy:
$$ \pi_\theta(a| \bar{s}) \rightarrow \pi_\theta(a|\bar{s}, z_i) $$
Q-function:
$$ Q_{\phi} (\bar{s}, a) \rightarrow Q_\phi(\bar{s},a,z_i) $$
Analogous to multi-task supervised learning: stratifies sampling, soft/hard weight sharing, etc.
The different about RL:
- The data distribution is controlled by the agent
- You may know what aspect(s) of the MDP are changing across tasks
Goal-conditioned RL with Hindsight Relabeling

Relabeling Strategies: Use any state from the trajectory.
The result is the exploration challenges alleviated, see more: Hindsight Experience Replay
Multi-task RL with Relabeling

随机未标记的交互作用在达到最后一个状态的0/1奖励下是最优的。

Unsupervised Visuo-motor Control through Distributional Planning Networks
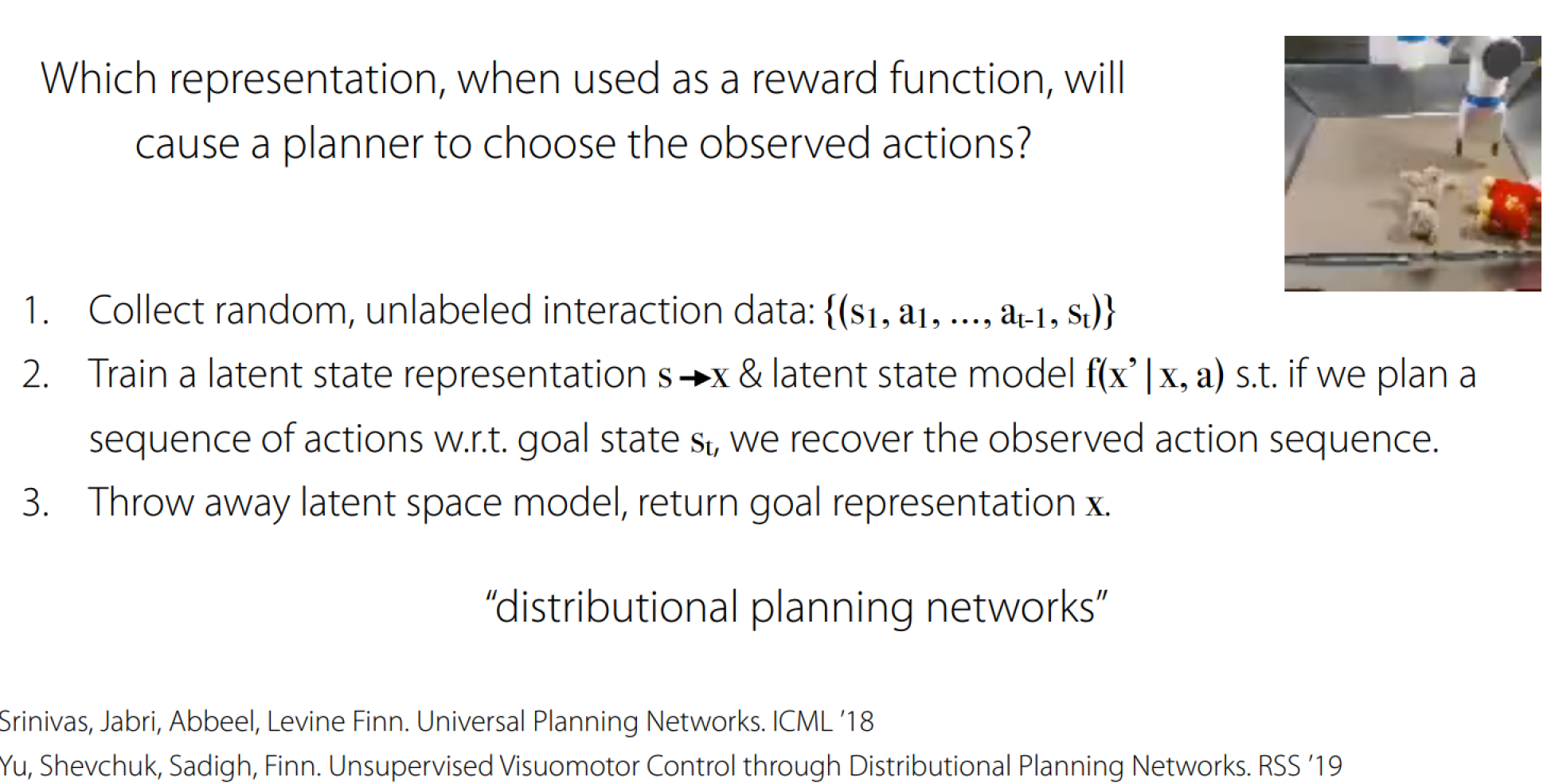
Note: Cover Picture