Model-based RL
Main idea: learn model of environment.
Reasons:
- Often leads to better efficiency
- Model can be reused
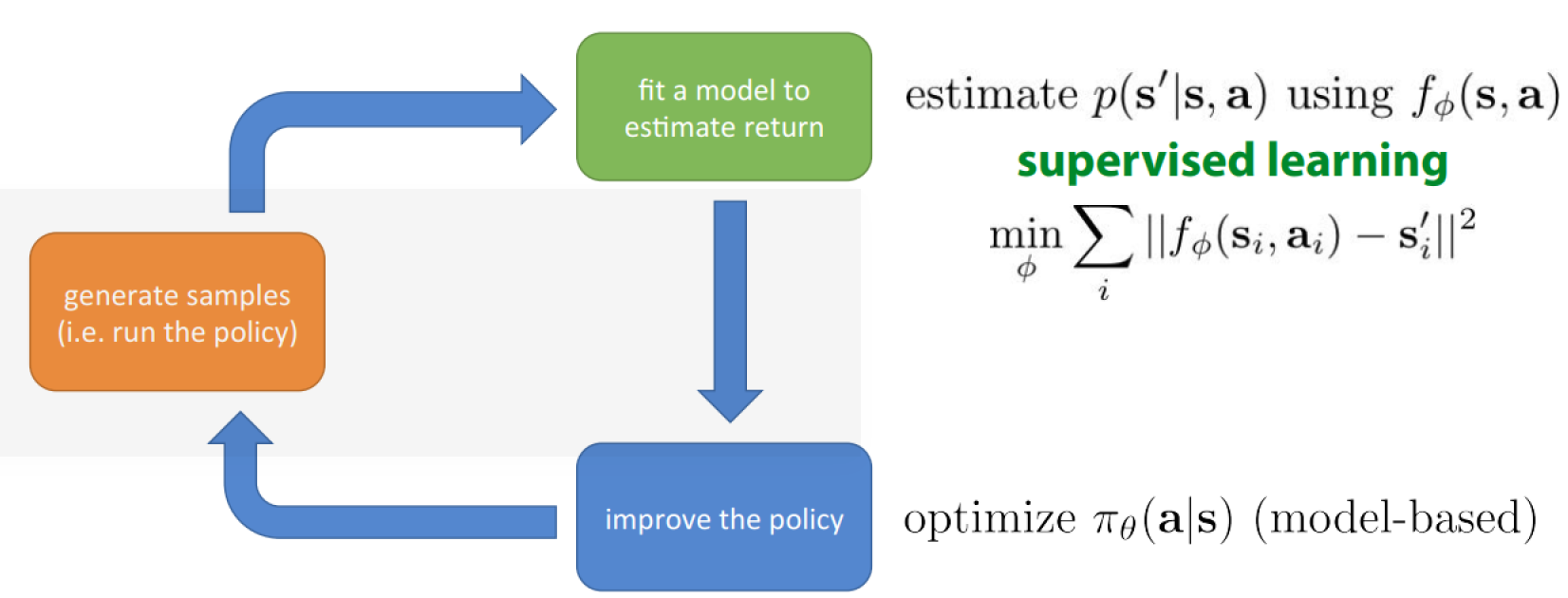
Gradient-based Optimization
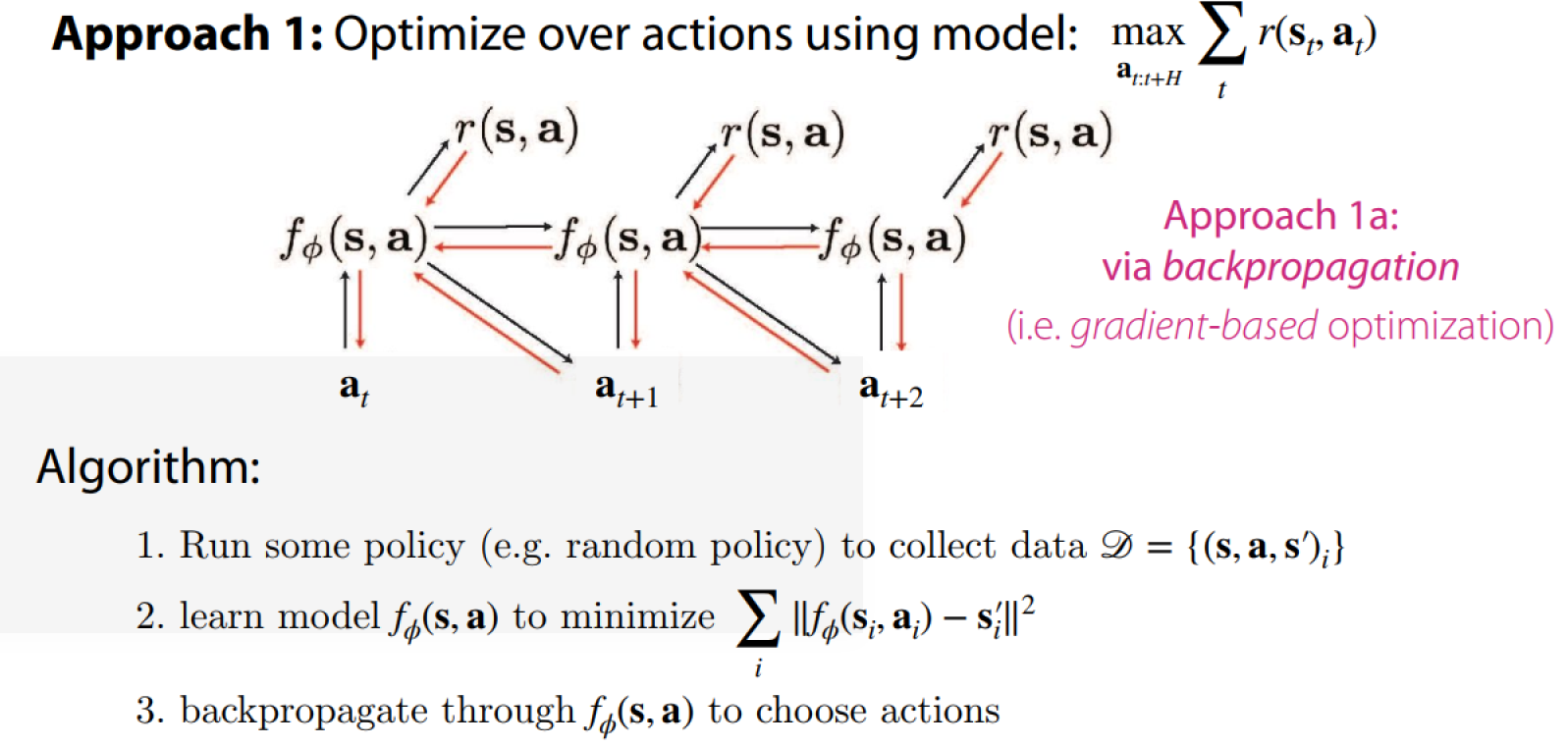
Gradient-free Optimization
Action optimization will exploit imprecisions in model. Refitting model using new data will help.
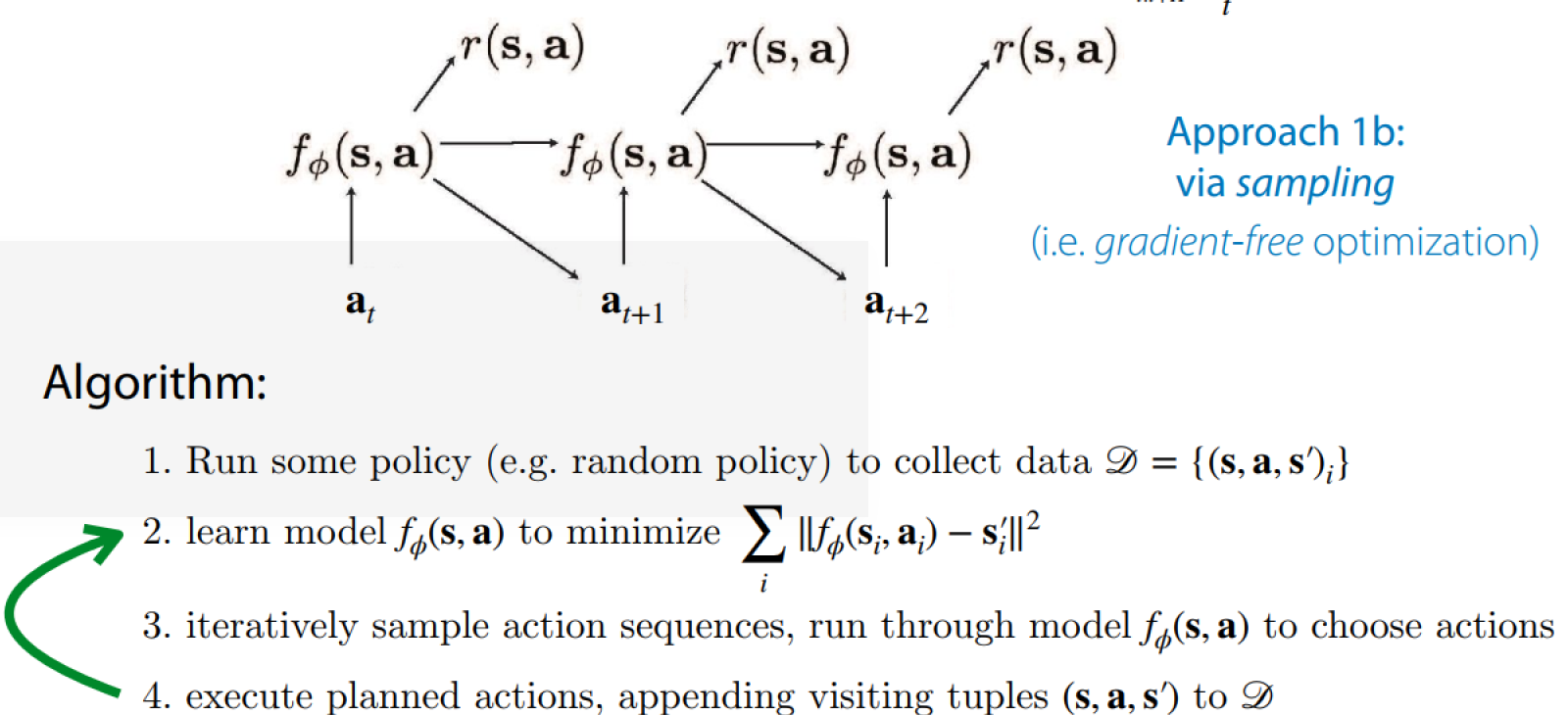
But generally, learning a good global model is hard.
Model-predictive Control(MPC)

Do you know the form of the rewards $r_i(s,a)$ for each task:
Yes
- you can learn a single model and plan w.r.t each $r_i$ at test time.
- Be careful about the reward will change how you collect data
- Model-based RL is sample efficient enough to train on real hardware
No
- Multi-task RL: learn $r_\theta(s,a,z_i)$, use it to plan
- Meta-RL: meta-learn $r_\theta(s,a,D_i^{tr}$, use it to plan
- Both solve the multi-task RL & meta-RL problem statements
Model-based RL with Image Observations

Approaches:
- Learn model in latent space
- Learn model of observations(e.g. video)
- Predict alternative quantities
Learning in Latent Space
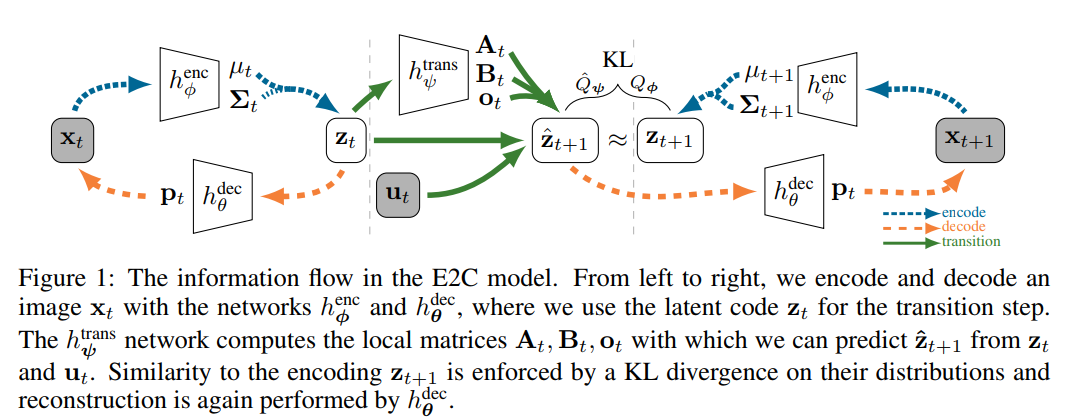
Key idea: learn embedding $s_t = g(o_t)$, then do model-based RL in latent space.
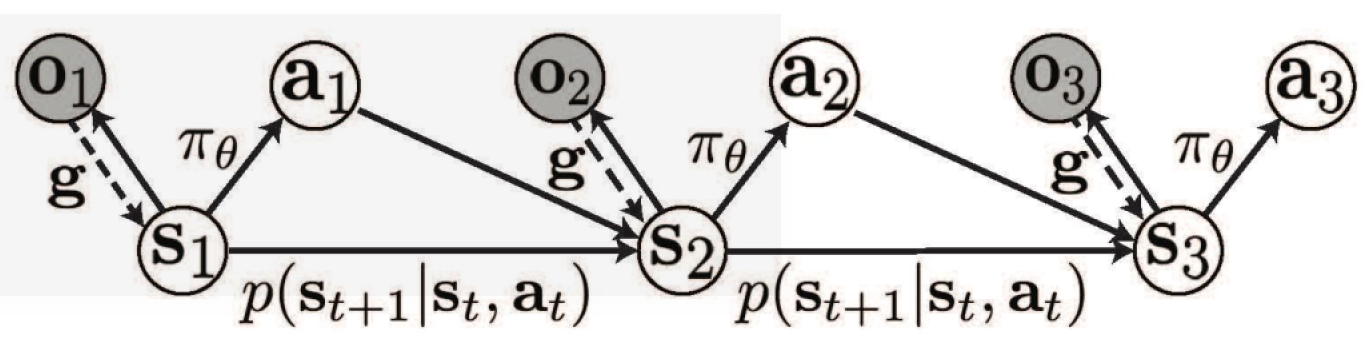
Algorithm:

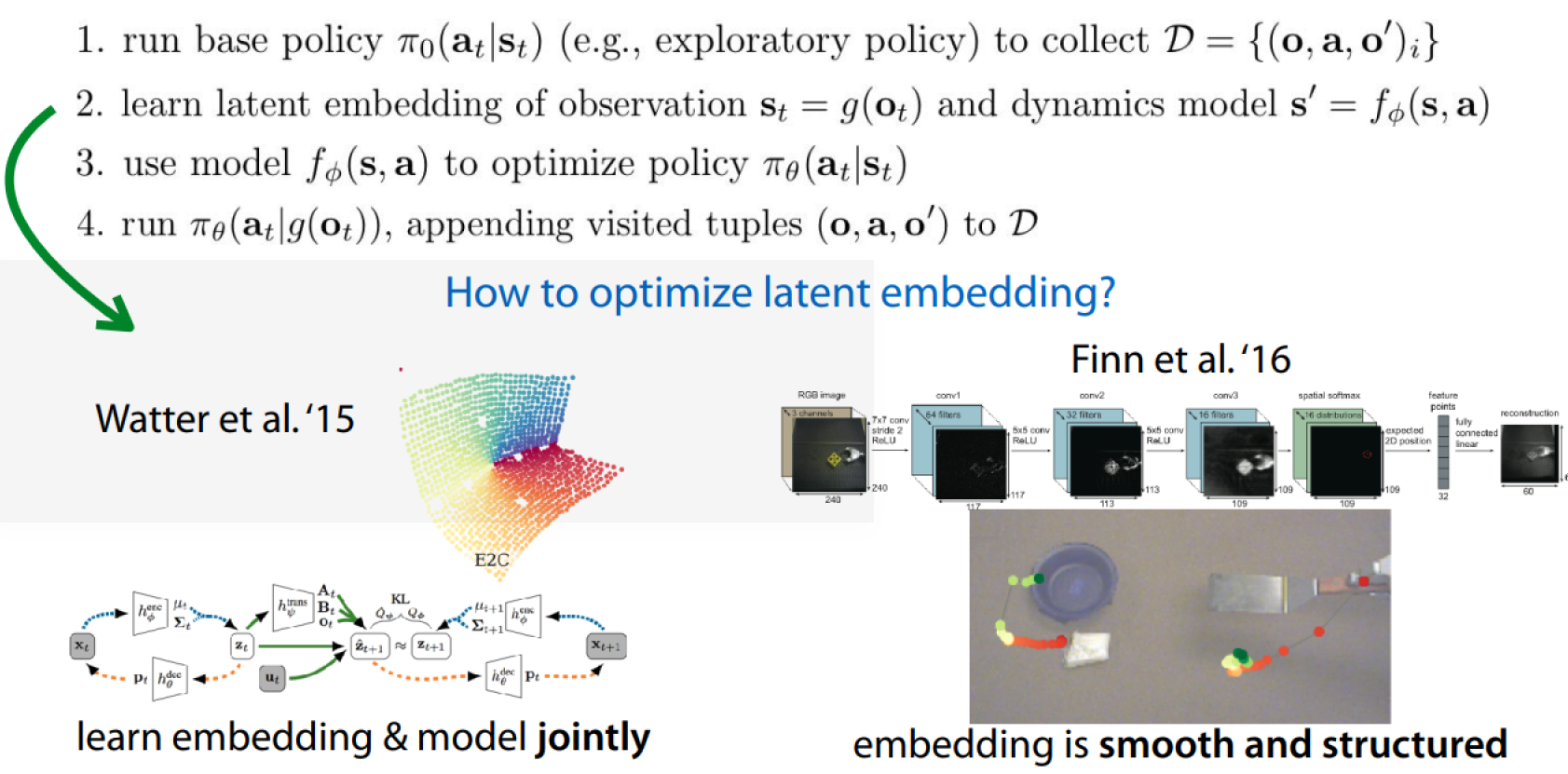
See more:
Learn embedding & model jointly:
Deep Spatial Autoencoders for Visuomotor Learning

Summary for Learning in Latent Space
Pros:
- Learn complex visual skills very efficiently
- Structured representation enables effective learning
Cons:
- Reconstruction objectives might not recover the right representation
Need better unsupervised representation learning methods.
Models Directly in Image Space
MPC重点分为三步:
- 第一步利用一个随机策略采集样本作为数据集。
- 第二步利用采集到的样本数据集训练一个环境模型
- 利用环境模型优化动作序列
具体实例如下:

如何预测视频中的下一帧:
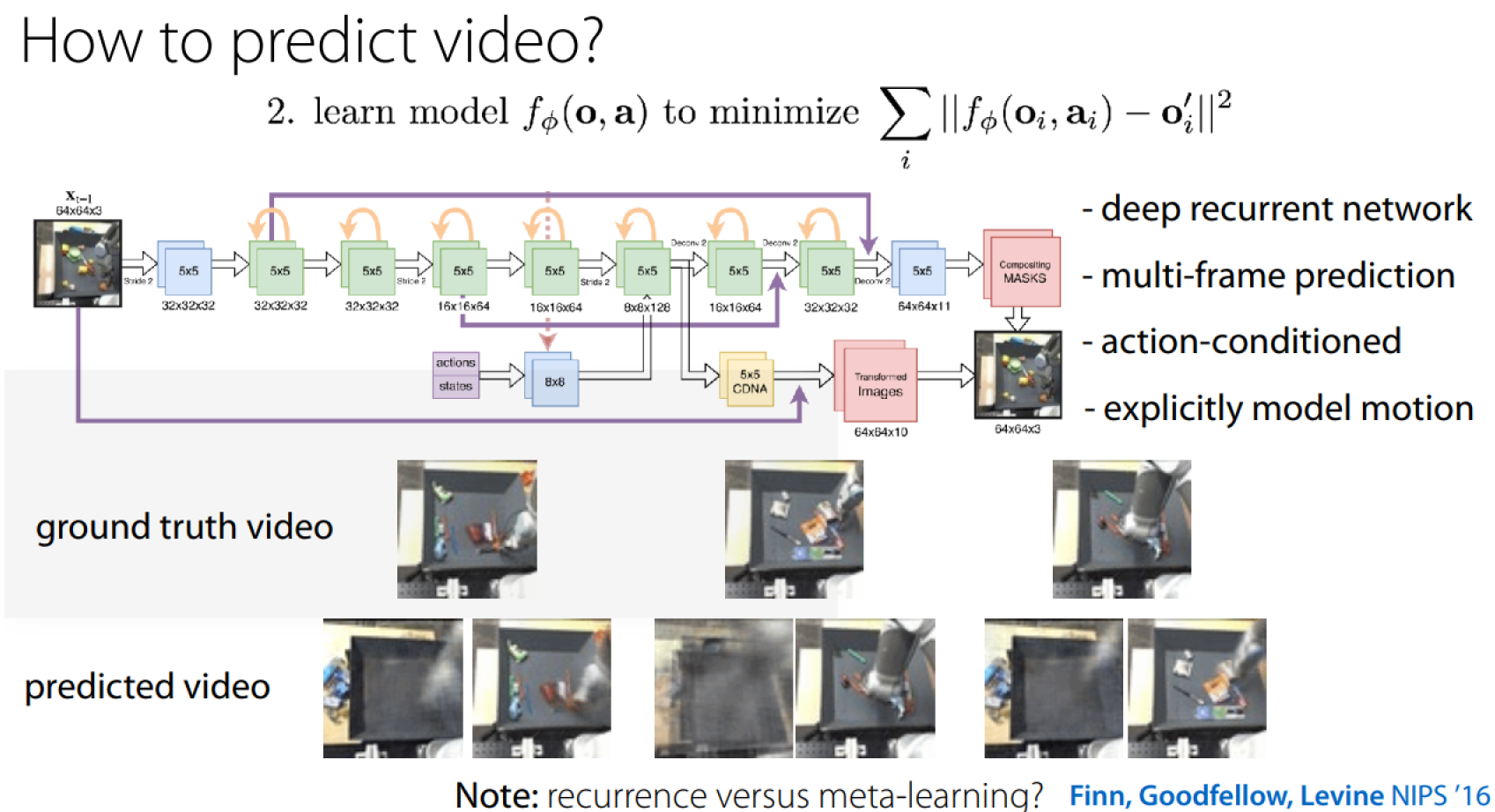
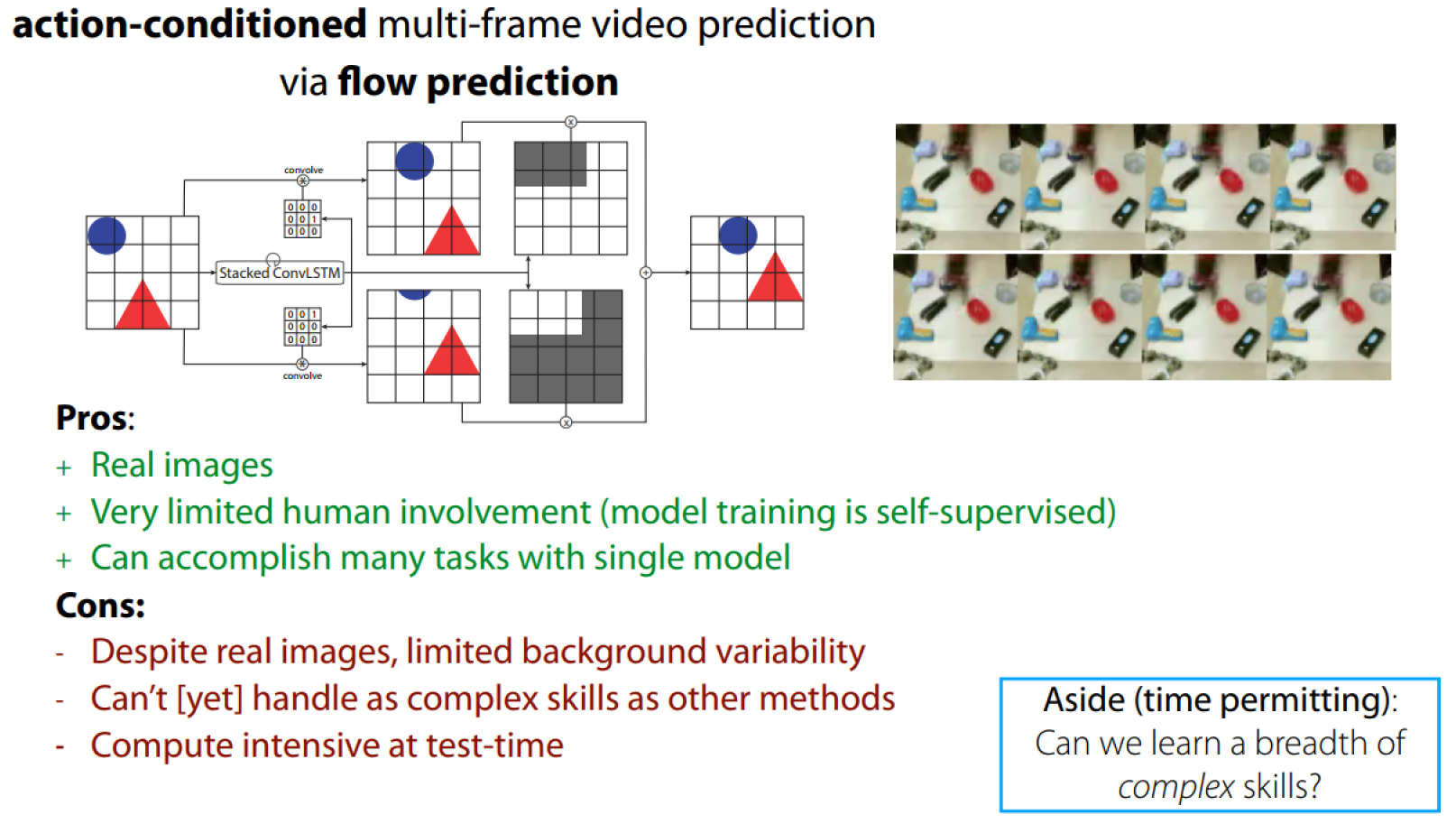
如何规划:
- Consider potential action sequences
- Predict the future for each action sequence
- Pick best future & execute corresponding action
- Repeat 1-3 to replan in real time
这是基于视觉的Visual “model-predictive control”(MPC).
具体案例如下:
See more from Deep visual foresight for planning robot motion
改进版本:
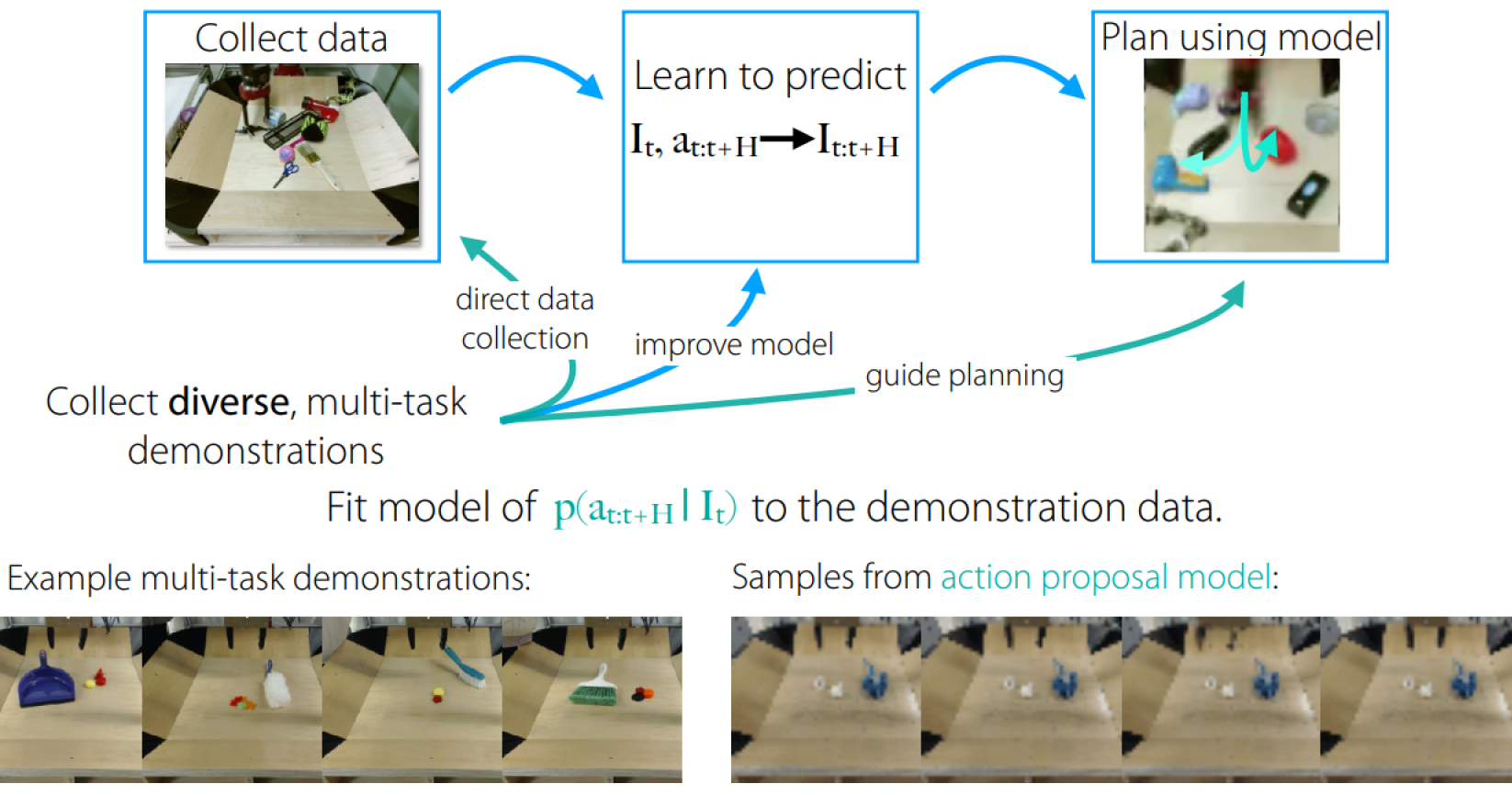
See more from Improvisation through Physical Understanding
Predict Alternative Quantities
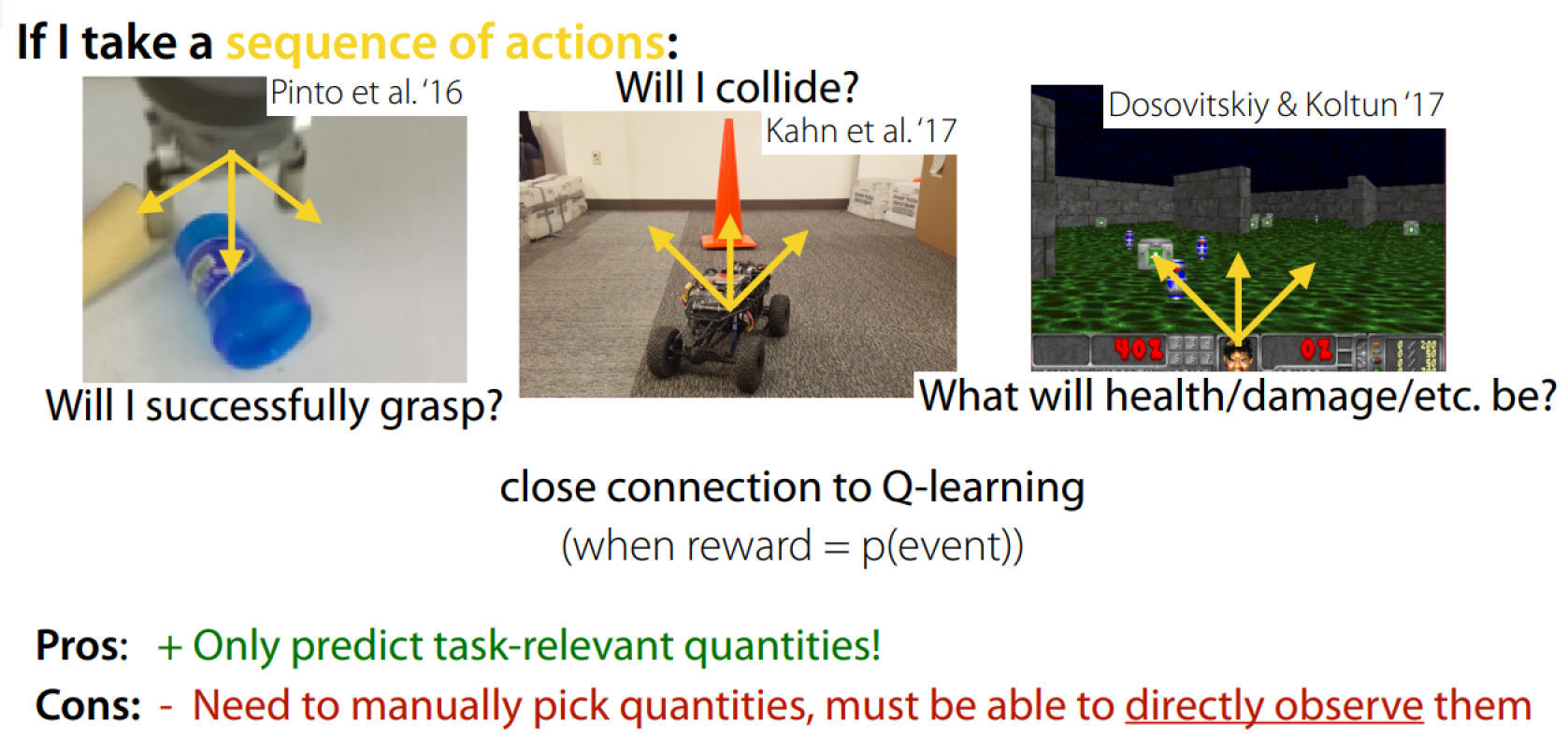
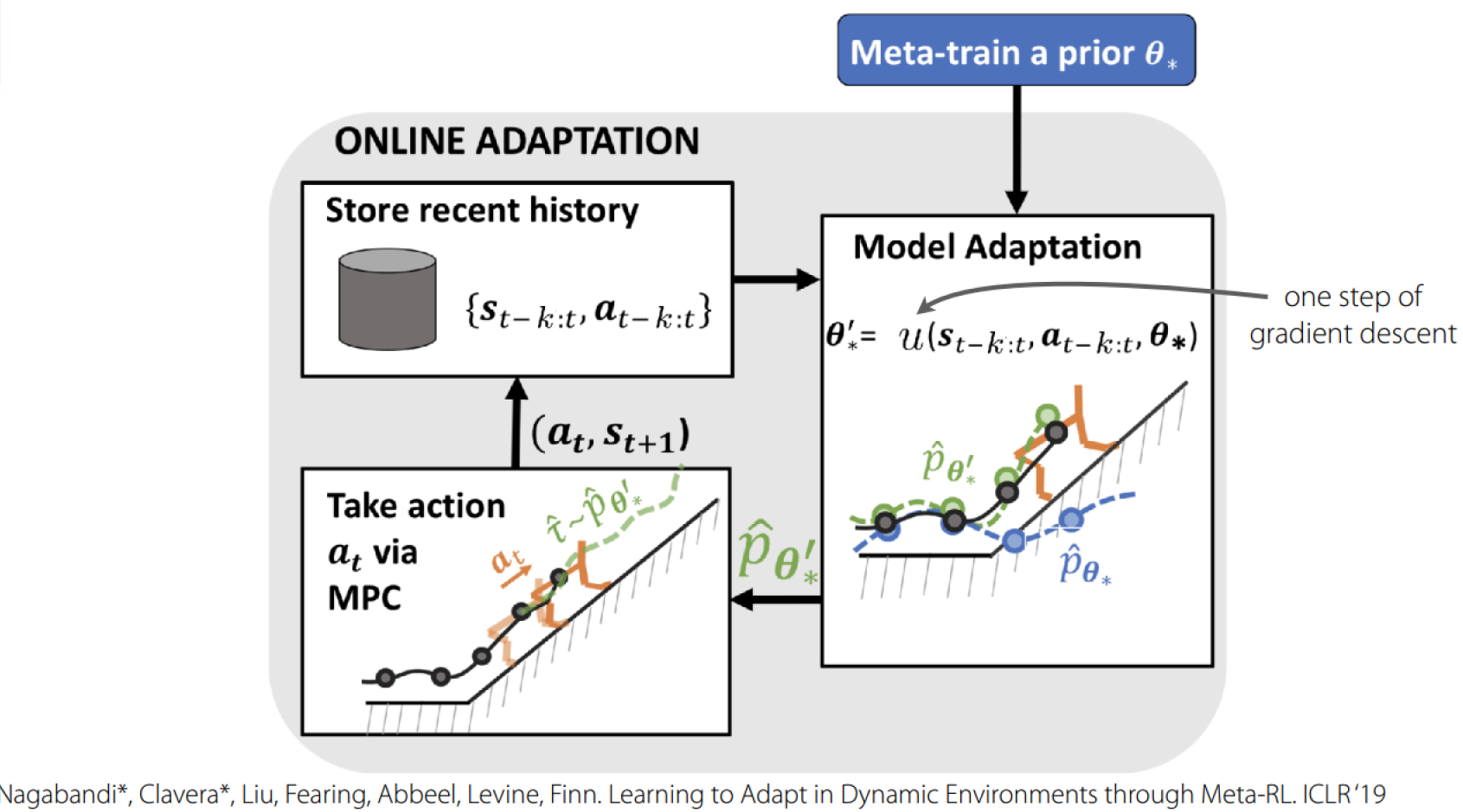
Model-Based Meta-RL
What is a RL Task
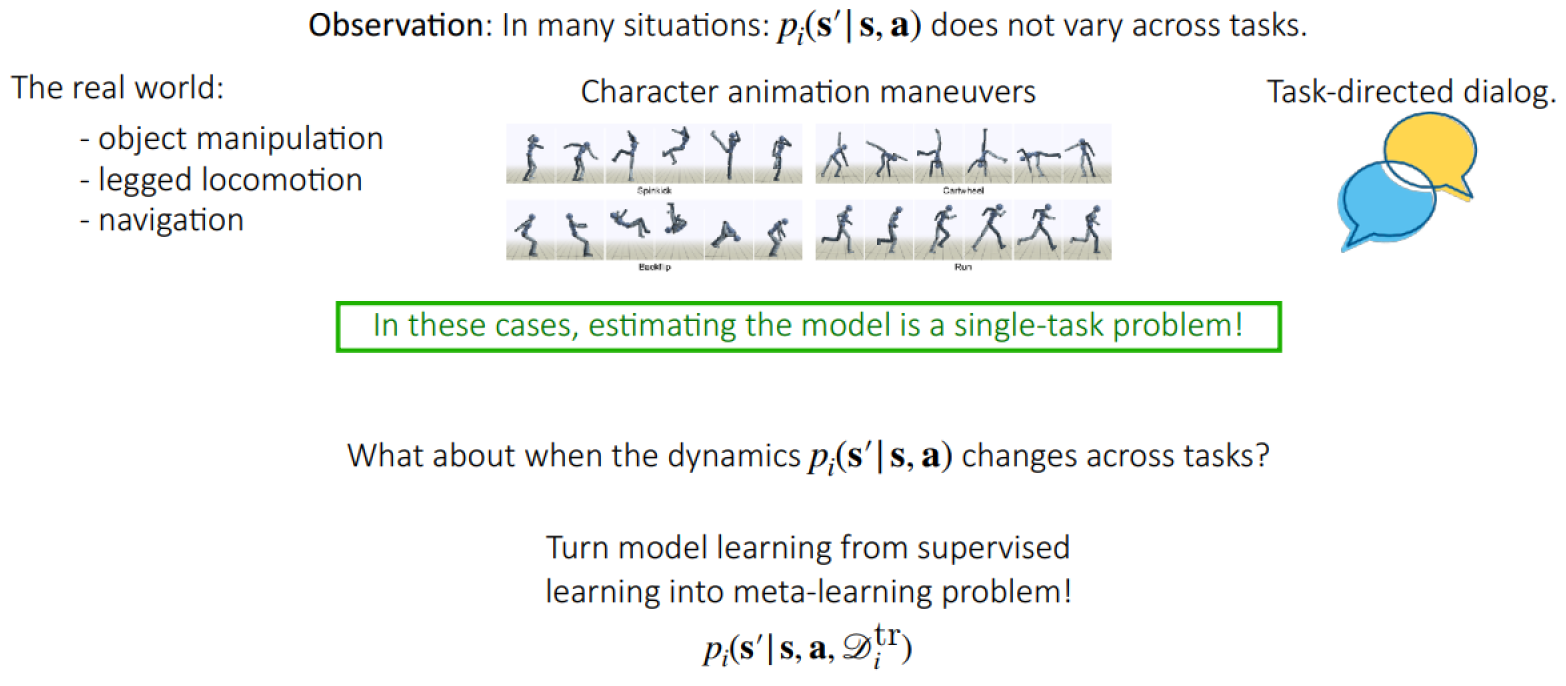
Deriving tasks from dynamic environments:
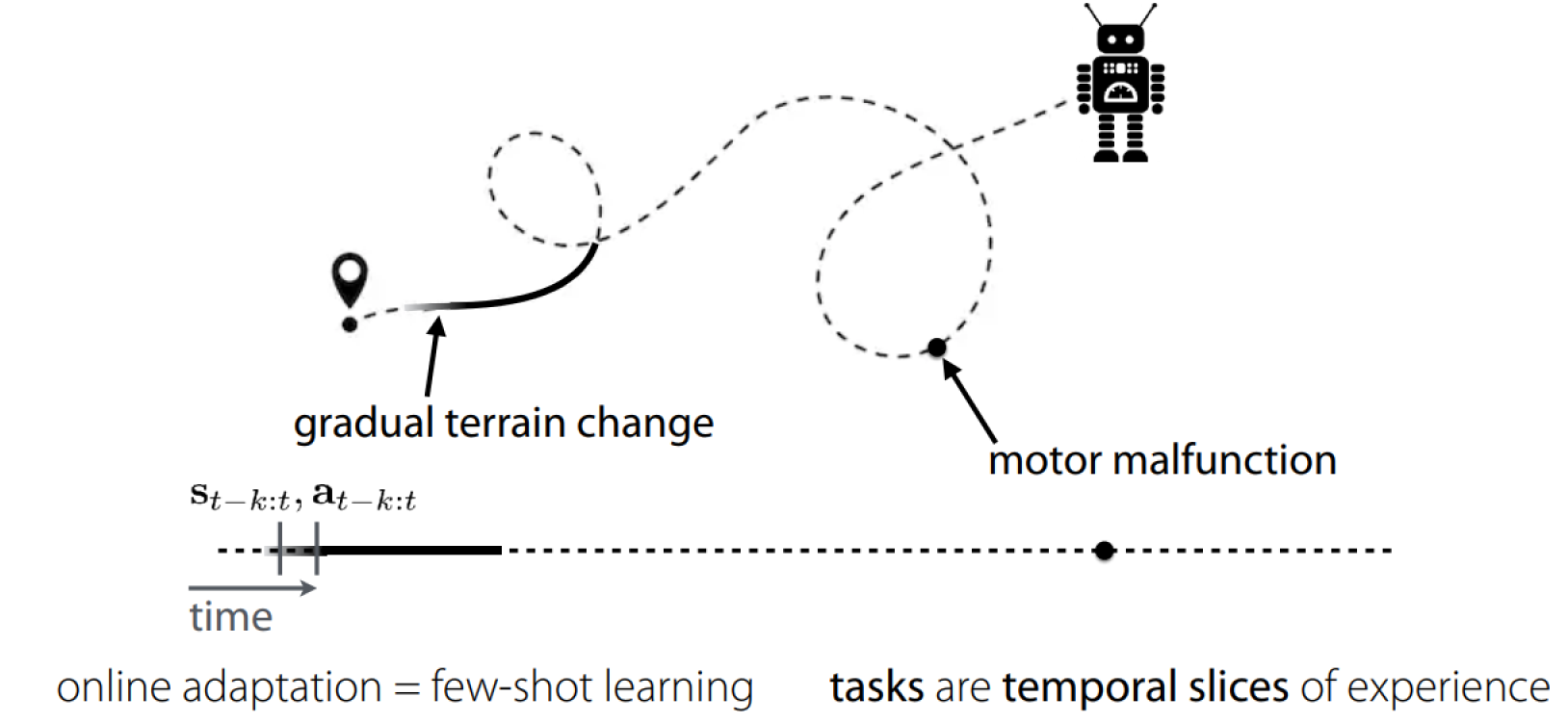
具体案例如下:
See more from Learning to Adapt Meta-Learning for Model-Based Control
Model-Based vs Model-Free
Model-based
- Easy to collect data in a scalable way (self-supervised)
- Easy to transfer across rewards
- Typically require a smaller quantity of reward-supervised data
- Models don’t optimize for task performance
- Sometimes harder to learn than a policy
- Often need assumptions to learn complex skills (continuity, resets)
Model-Free
- Makes little assumptions beyond a reward function
- Effective for learning complex policies
- Require a lot of experience (slower)
- Harder optimization problem in multi-task setting
Note: Cover Picture