Why Robots
- Robots can teach us things about intelligence
- Faced with the real world
- Must generalize across tasks, objects, environments, etc
- Need some common sense understanding to do well
- Supervision can’t be taken for granted
Before: Learn one task in one environment, starting from scratch, rely on detailed supervision and guidance.
Robots are specialists(single task), but humans are generalists(multi tasks).
Deep learning allows us to handle unstructured inputs(pixels, language, sensor readings, etc.) without hand-engineering features, with less domain knowledge.
Why Deep multi task and meta learning
- It’s impractical to learn from scratch for each disease, each robot, each person, each language, each task
- If your data has a long tail, this setting breaks standard machine learning paradigms
You can quickly learn something new by leveraging prior experience.

Critical Assumption
Different tasks need to share some structure. If this doesn’t hold, you are better off using single-task learning.
Problem Definitions
The multi-task learning problem: Learn all of the tasks more quickly or more proficiently than learning them independently. The meta-learning problem: Given data/experience on previous tasks, learn a new task more quickly and/or more proficiently.
Multi-Task Learning Basics
Notation
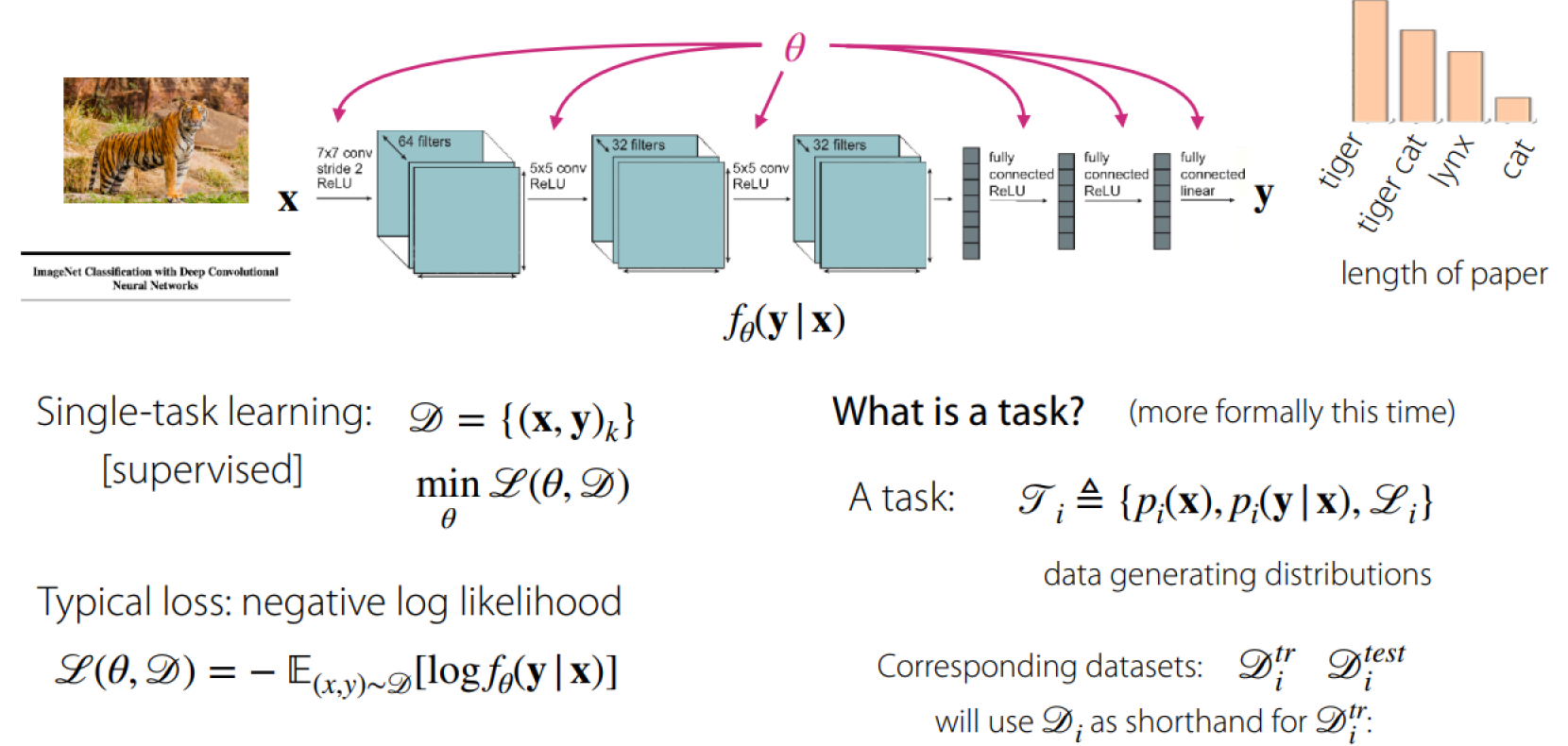
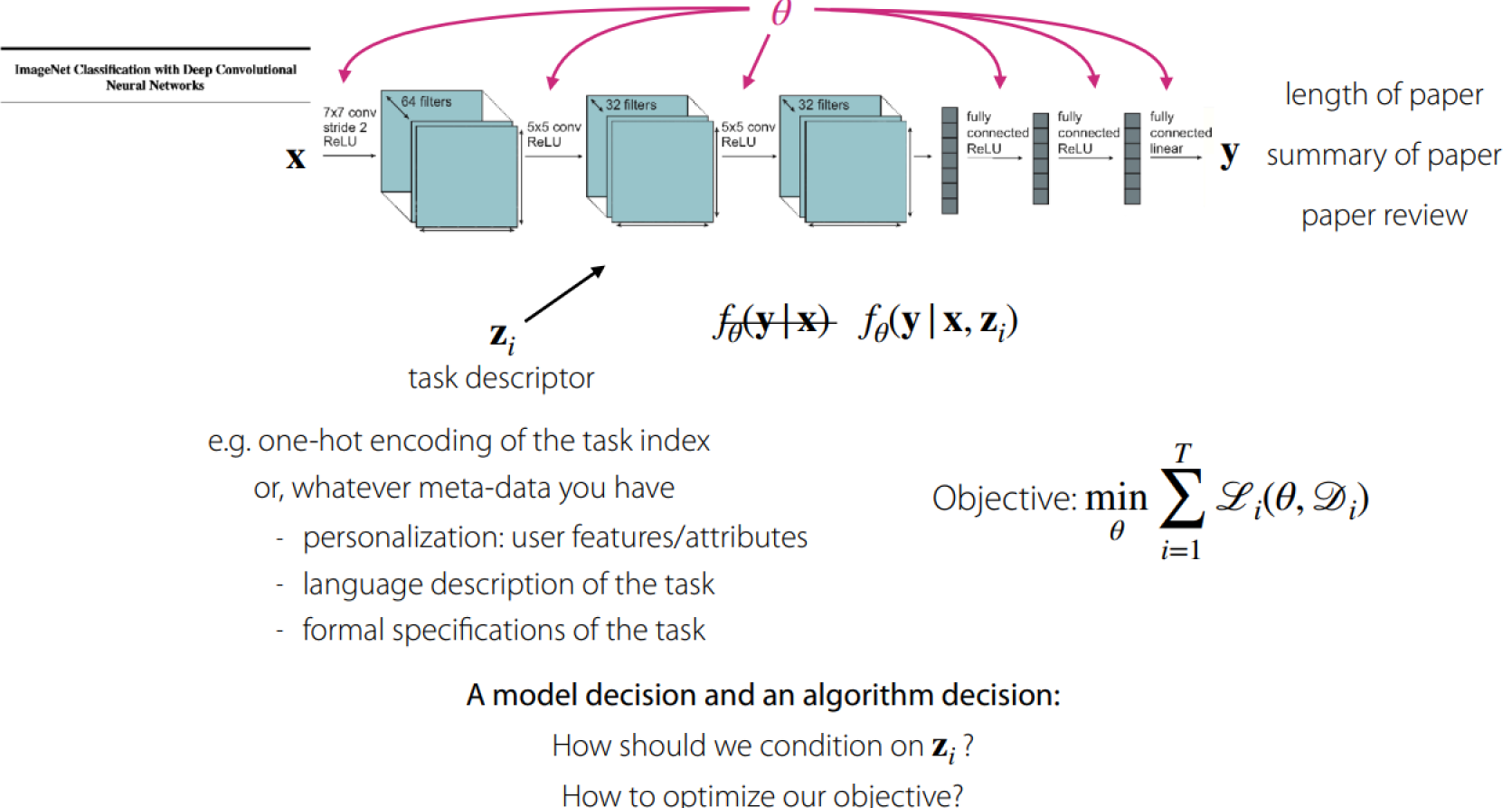
If $Z_i$ is the task index, one way to solve the problem is conditioning on the task like below:
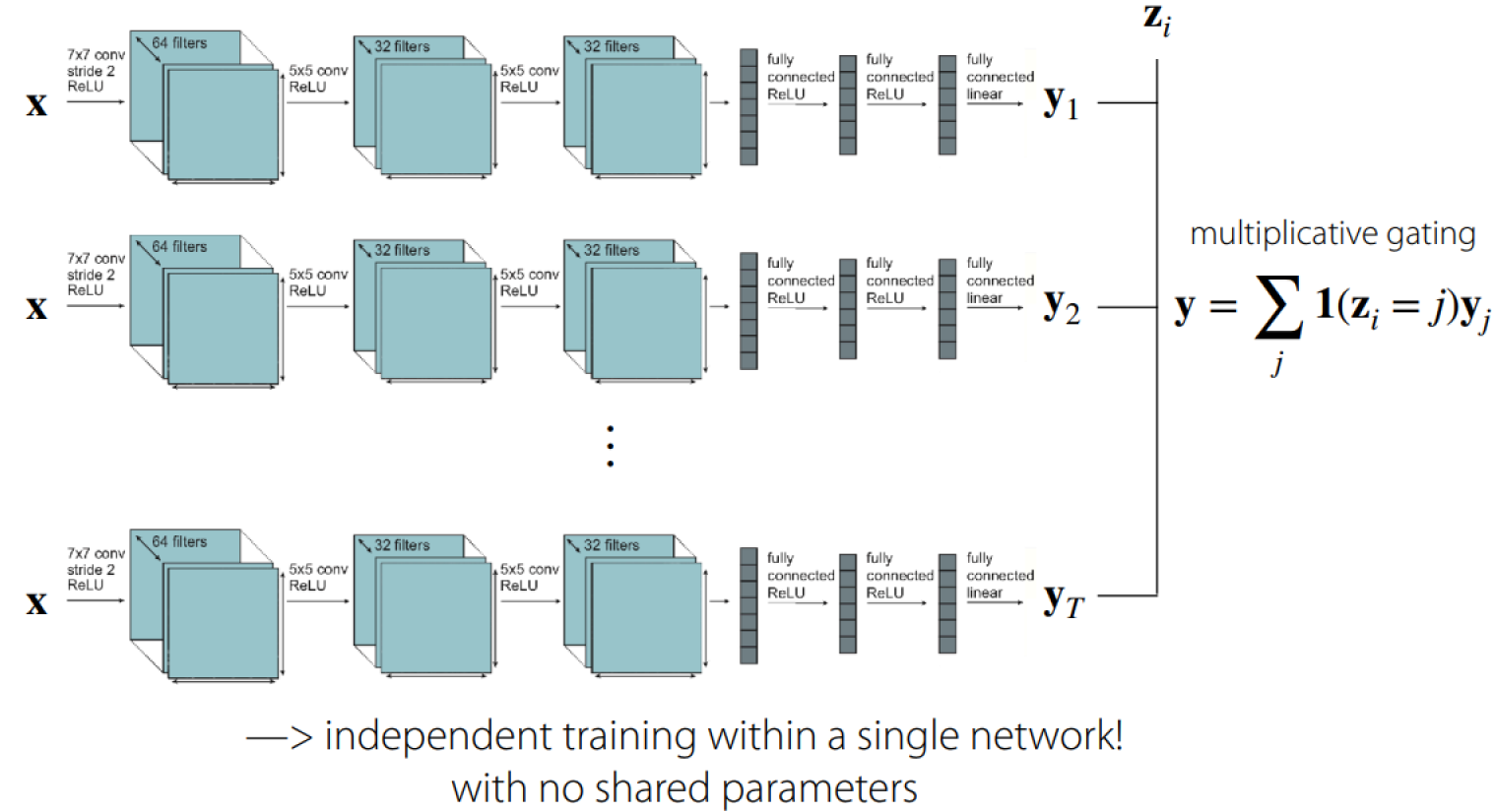
方法一:直接在模型输出最后进行门限控制
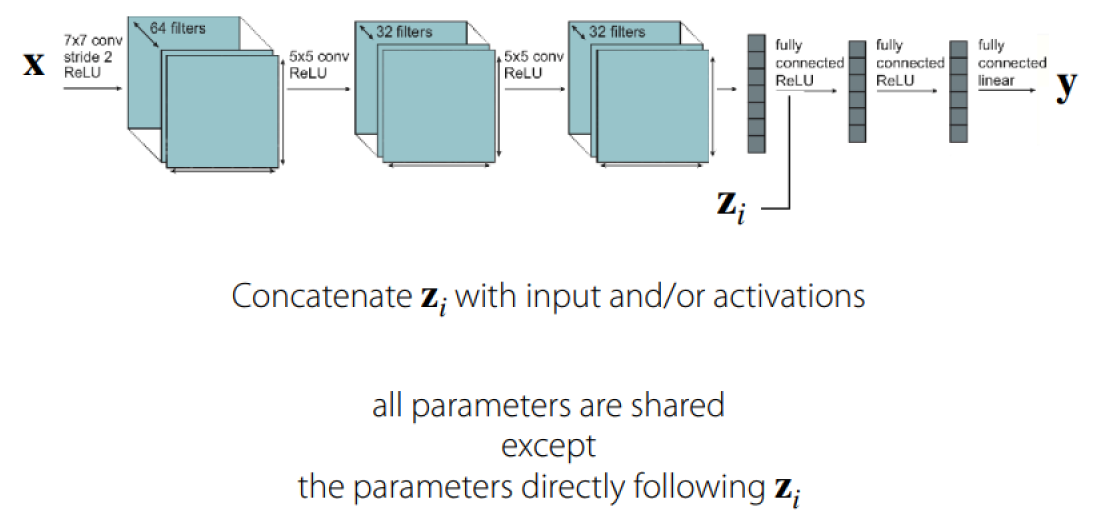
方法二:在模型中间添加特定任务的信息
方法三:将参数分解成两部分看待

针对多任务的常见方法有:
- Concatenation-based conditioning
- Additive Conditioning
- Multi-head architecture
- Multiplicative conditioning
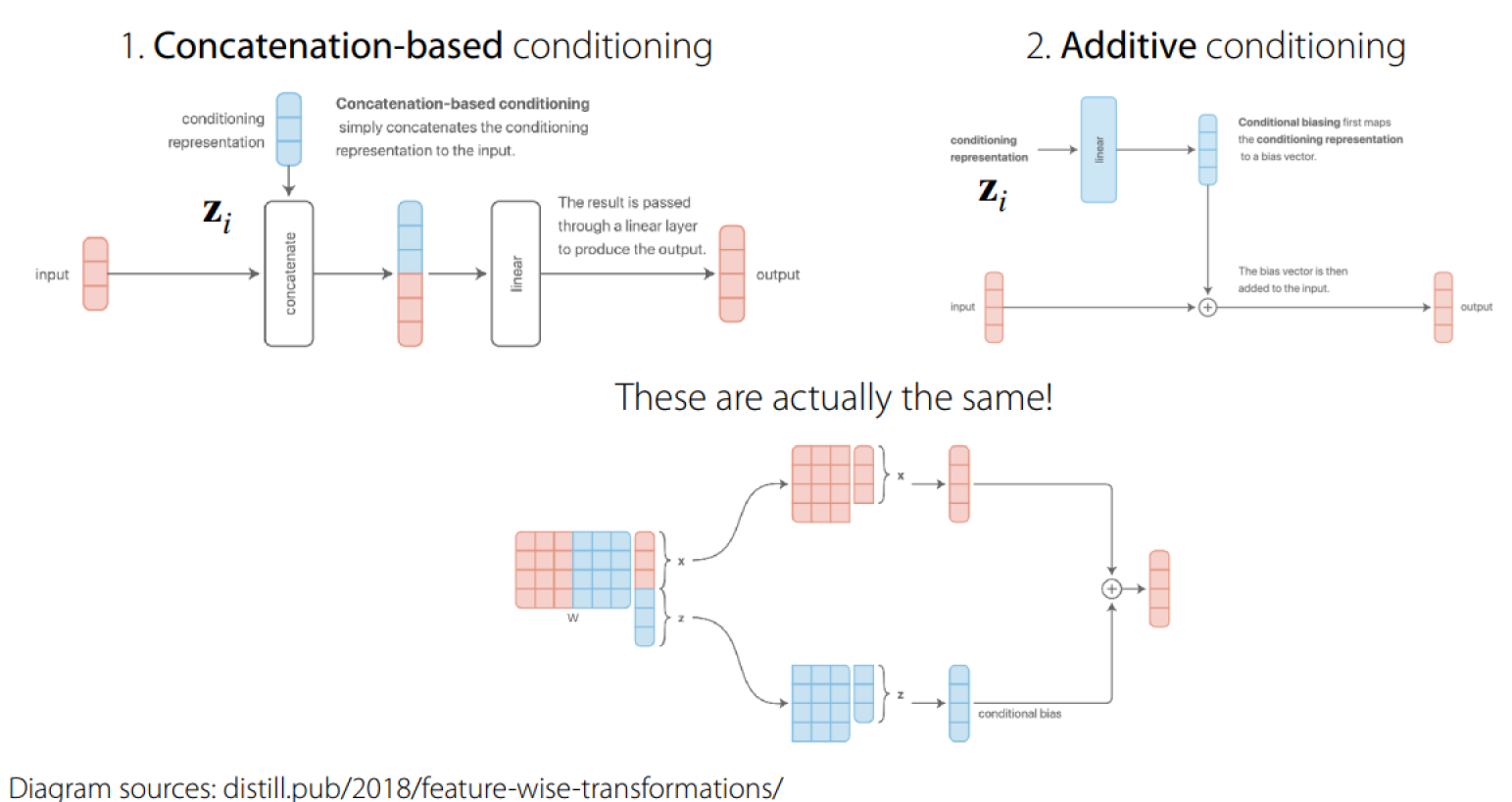
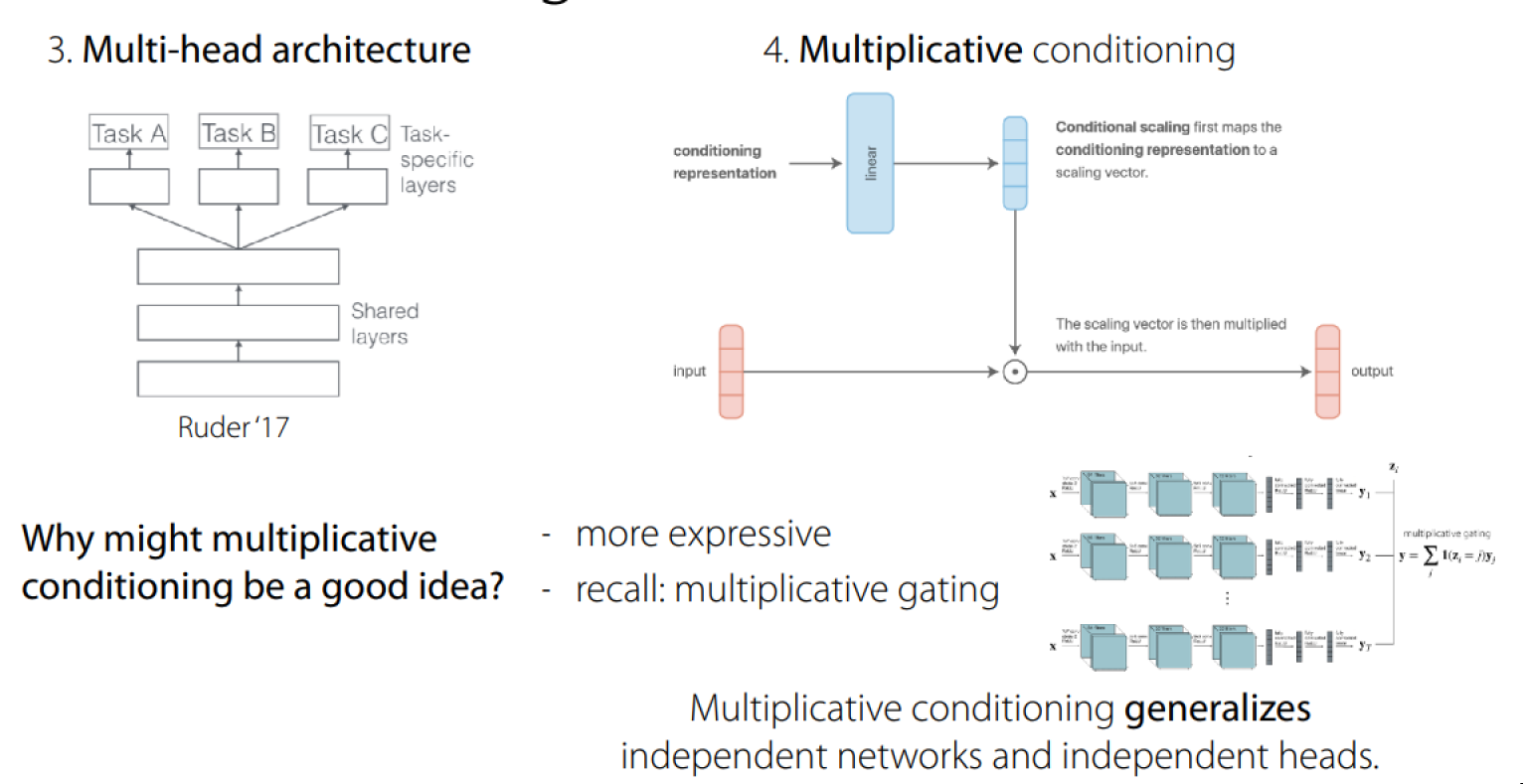
更复杂的方法如下:
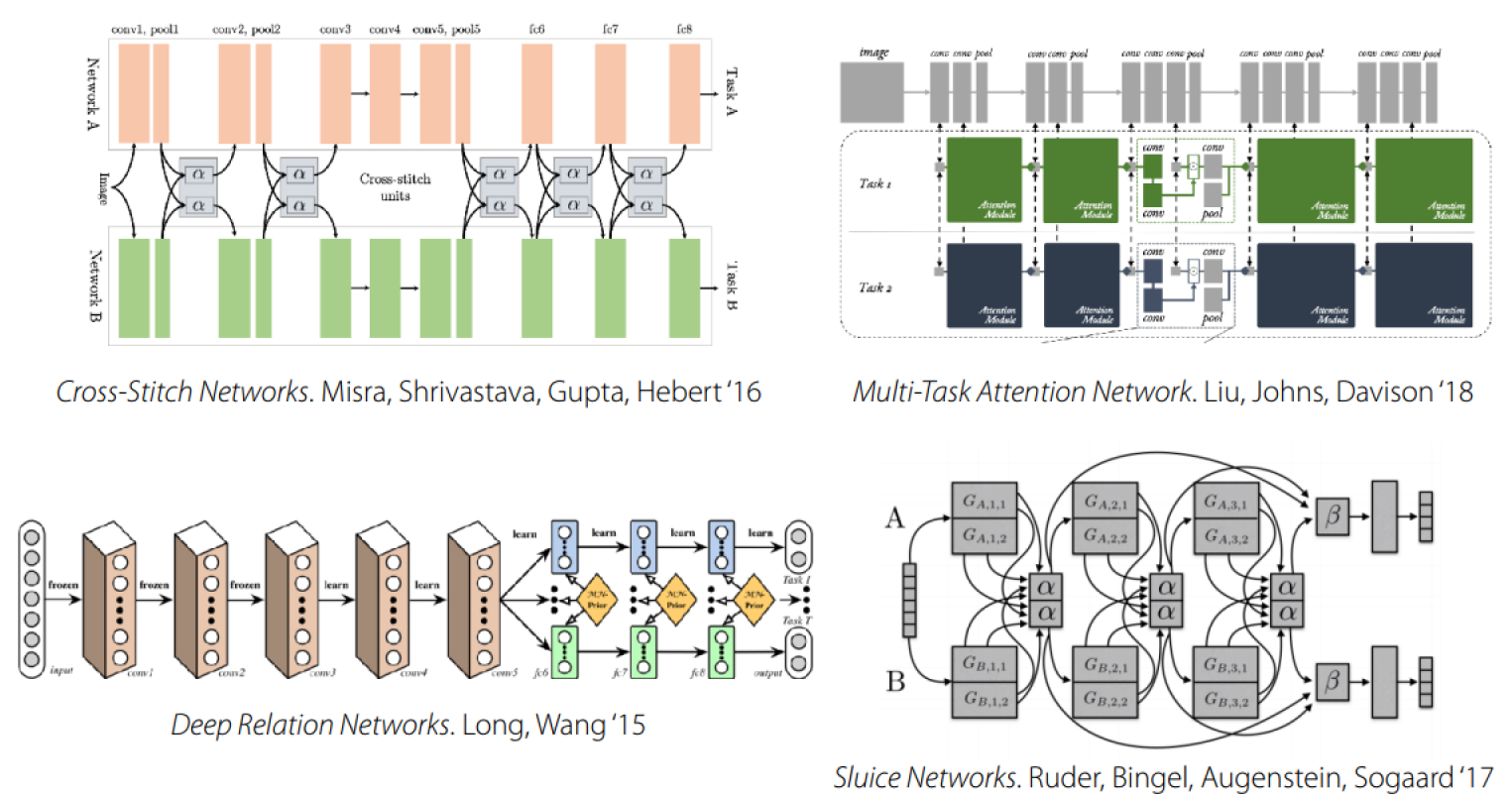
上面的方法更多的是在做神经网络结构的微调,它们是:
- Problem dependent
- Largely guided by intuition or knowledge of thew problem
- Currently more of an art than a science
Optimizing the Objective

This ensures that tasks are sampled uniformly, regardless of data quantities. For regression problems, make sure your task labels are on the same scale.
Challenge
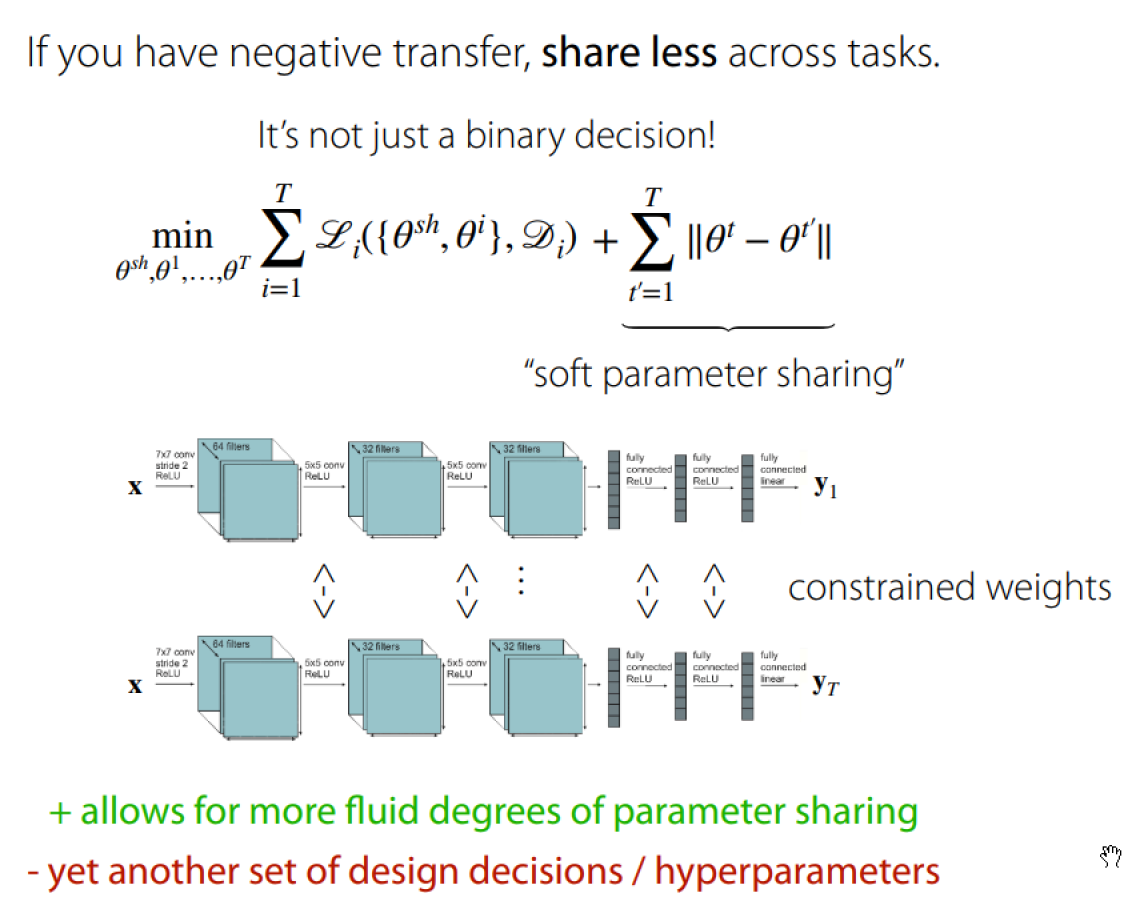
Negative Transfer
Negative Transfer: Sometimes independent networks work the best.
Why:
- Optimization challenges
- Caused by cross-task interference
- Tasks may learn at different rates
- Limited representational capacity
- Multi-task networks often need to be much larger than their single-task counter-parts
解决方案如下:
Overfitting
Multi-task learning is like a form of regularization and you may not be sharing enough. The solution is to share more.
Meta-Learning Basics
Two ways to view meta-learning algorithms:

The meta-learning problem:
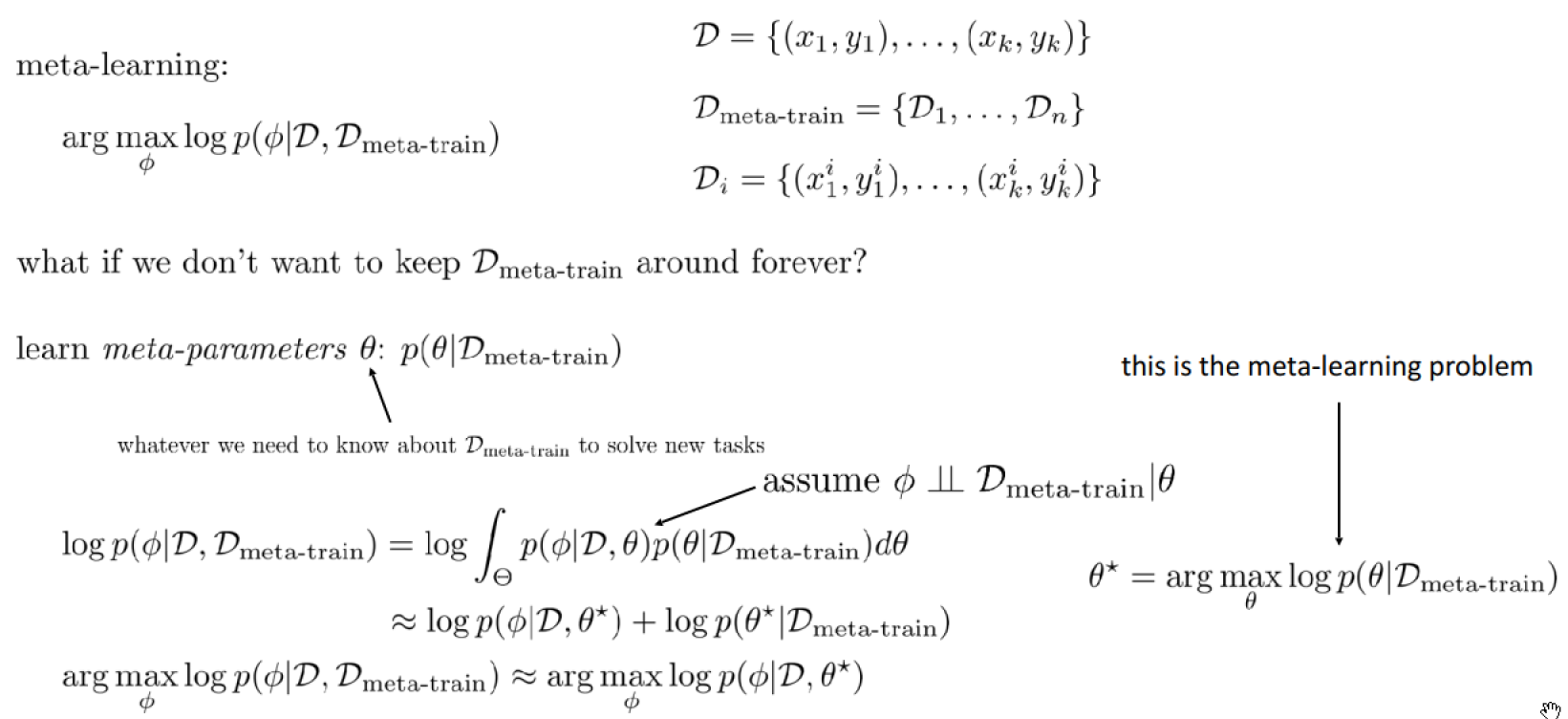
The complete meta-learning optimization:
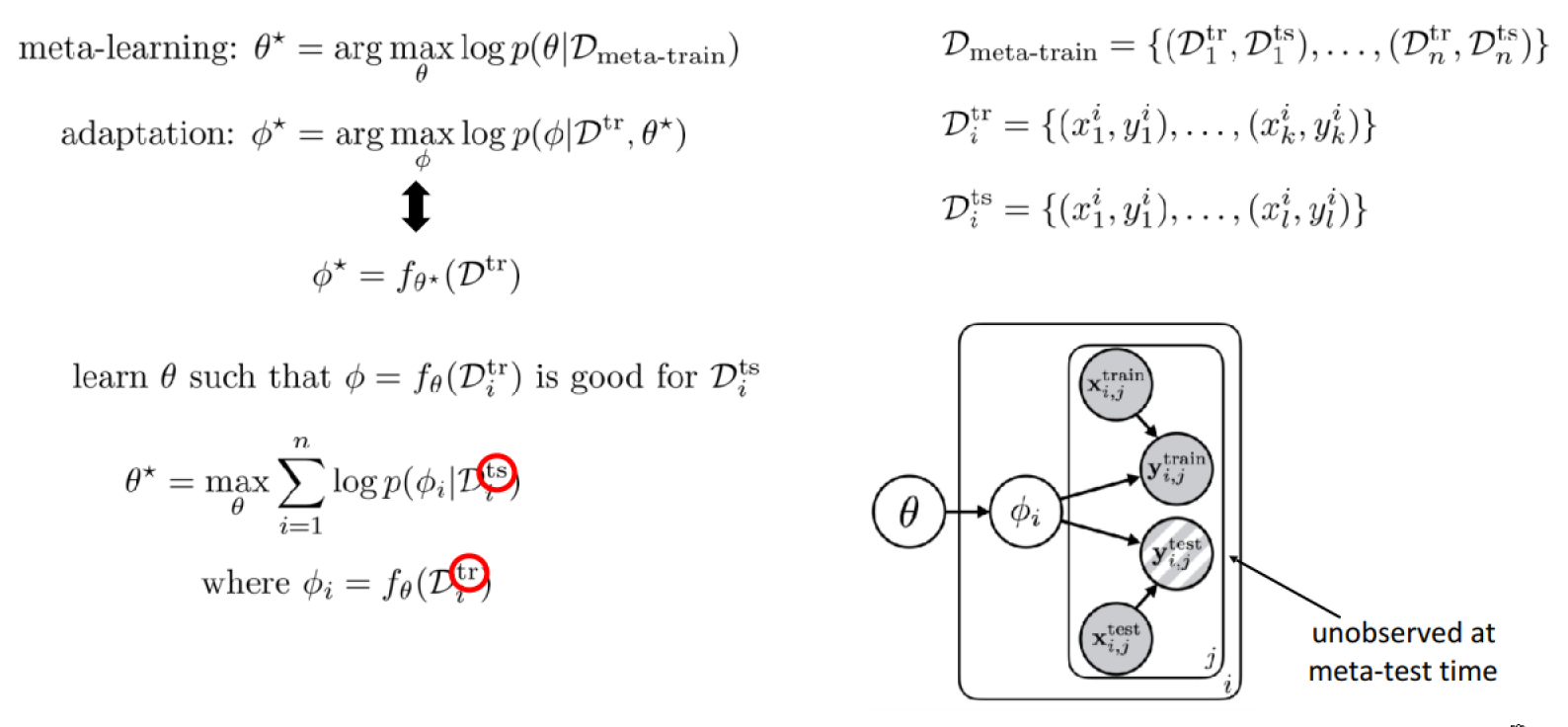
Closely related problem settings:

Note: Cover Picture