This is the note for full stack deep learning bootcamp course, the images and content are from their slides. For more detail, please go to their website.
Introduction
The history of deep learning:

Why Now
Three factors:
- Data
- Compute
- Some new ideas
Setting Up Machine Learning Projects
Lifecycle of a ML Project
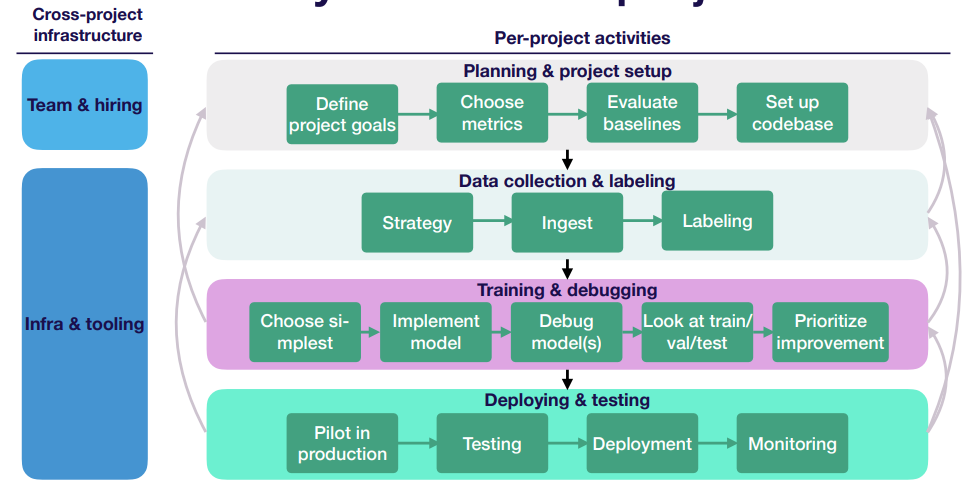
Prioritizing Projects & Choosing Goals
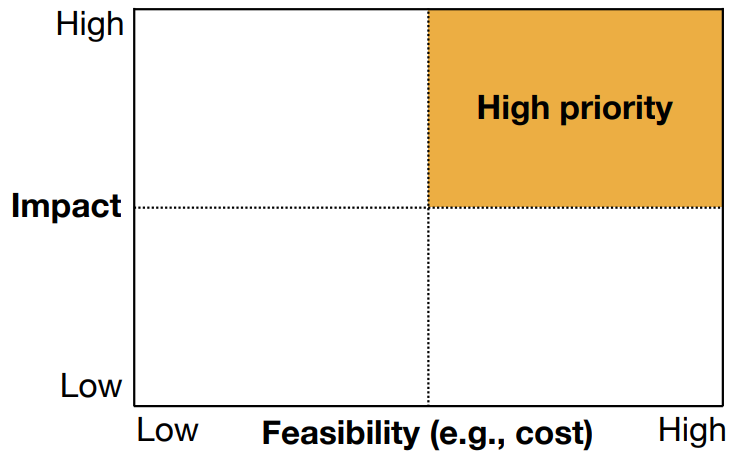
A general framework for prioritizing projects:
The Economics of AI
- AI reduces cost of prediction
- Prediction is central for decision making
- Cheap prediction means:
- Prediction will be everywhere
- Even in problems where it was too expensive before
- Implication: Look for projects where cheap prediction will have a huge business impact
From Prediction Machines: The Simple Economics of Artificial Intelligence(Agrawal, Gans, Goldfarb)
Software 2.0
From: Andrej Karpathy:
- Software 1.0 = Traditional programs with explicit instructions.
- Software 2.0 = Humans specify goals, and algorithm searches for a program that works
- 2.0 programmers work with datasets, which get compiled via optimization
- Implication: Look for complicated rule-based software where we can learn the rules instead of programming them
Assessing Feasibility of ML Projects
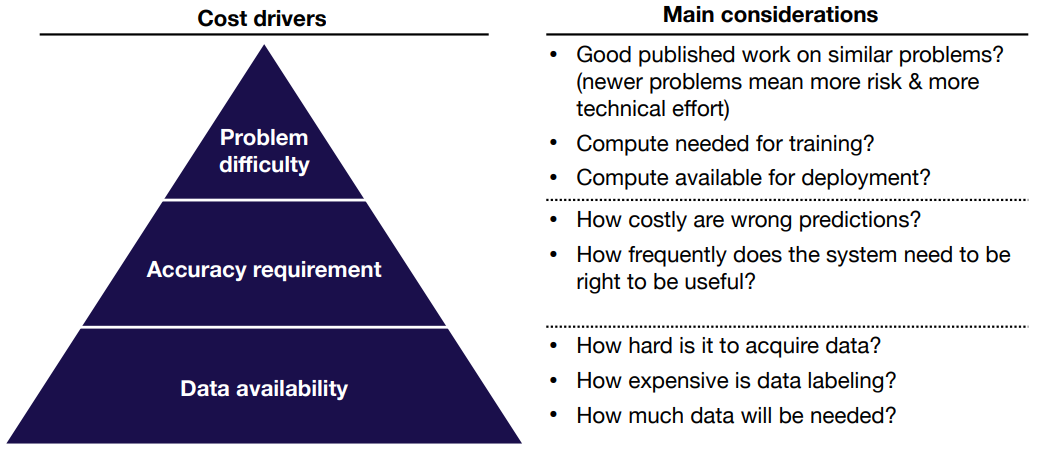
- ML project costs tend to scale super-linearly in the accuracy requirement
- Product design can reduce need for accuracy
Key points for prioritizing projects
- To find high-impact ML problems, look for complex parts of your pipeline and places where cheap prediction is valuable
- The cost of ML projects is primarily driven by data availability, but your accuracy requirement also plays a big role
Choosing Metrics
Accuracy, precision, and recall:
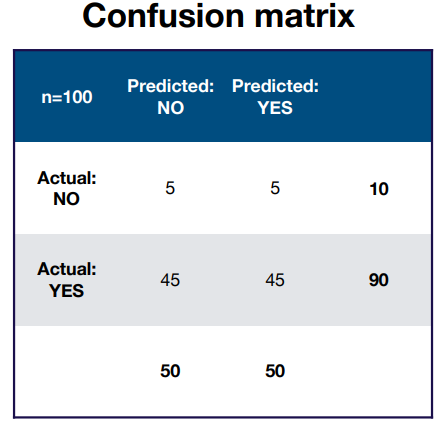
- Accuracy = Correct / Total = (5+45)/100 = 50%
- Precision = true positives / (true positives + false positives) = 45/(5+45) = 90%
- Recall = true positives / actual YES = 45/(45+45) = 50%
It’s hard to determine which model is the best using a single metric, so we could combine them together:
- Simple average / weighted average
- Threshold n-1 metrics, evaluate the nth
- More complex / domain-specific formula
For the domain-specific metrics like mAP:
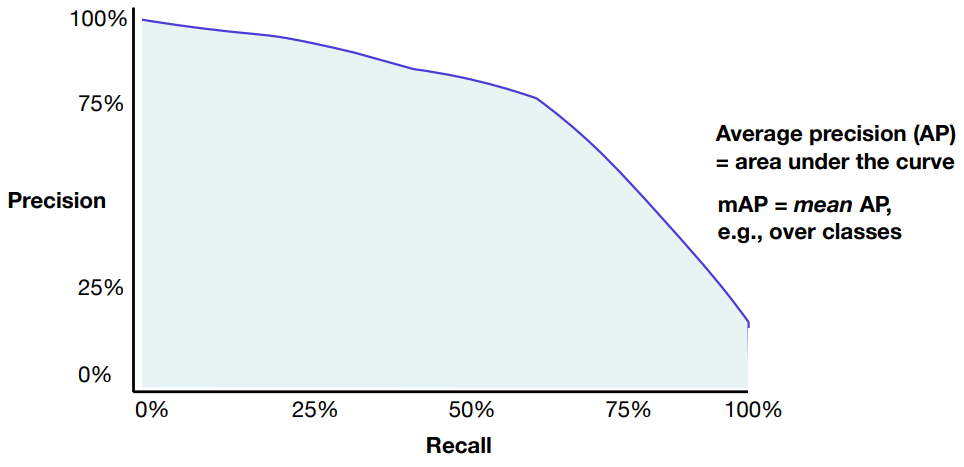
The results using combined metrics is shown below:
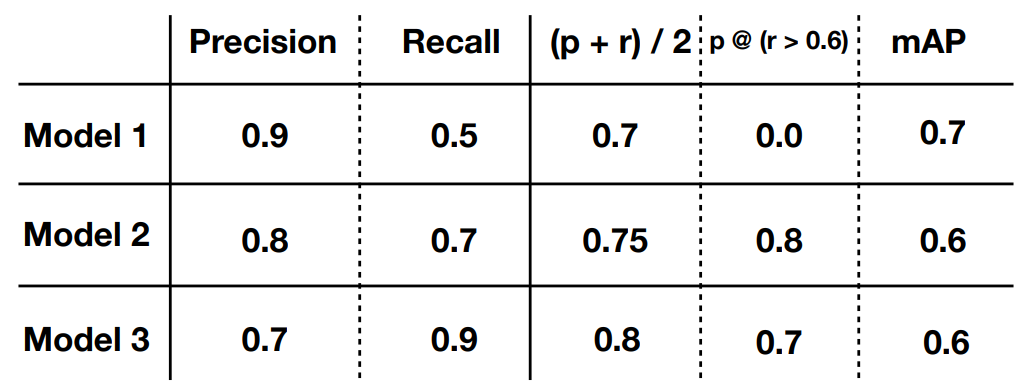
Key Points for Choosing a Metric
- The real world is messy; you usually carte about lots of metrics
- ML system work best when optimizing a single number
- Picking a formula for combining metrics. This formula can and will change
Choosing Baselines
Where to Look for Baselines
- External Baselines
- Business / engineering requirements
- Published results: make sure comparison is fair
- Internal Baselines
- Scripted baselines
- OpenCV scripts
- Rules-based methods
- Simple ML baselines
- Standard feature -based models
- Linear classifier with hand-engineered features
- Basic neural network model
- Scripted baselines
How to Create Good Human Baselines

Key Points for Choosing Baselines
- Baselines give you a lower bound on expected model performance
- The tighter the lower bound, the more useful the baseline
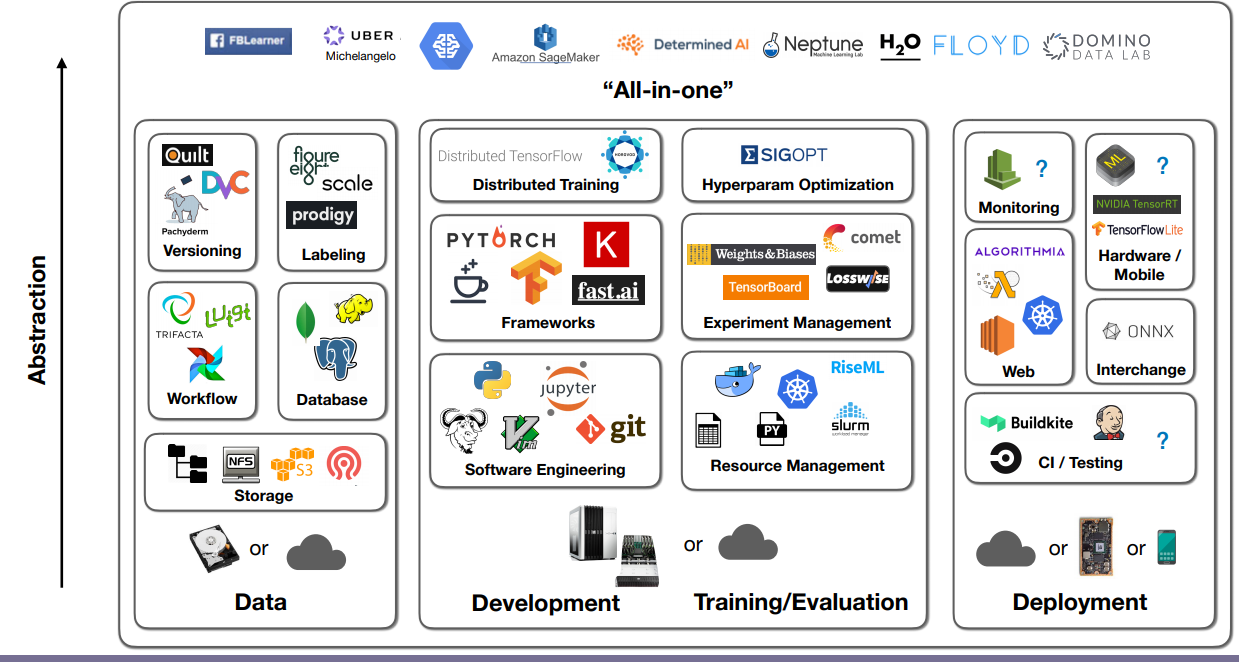
Infrastructure & Tooling
Full View of the DL Infrastructure
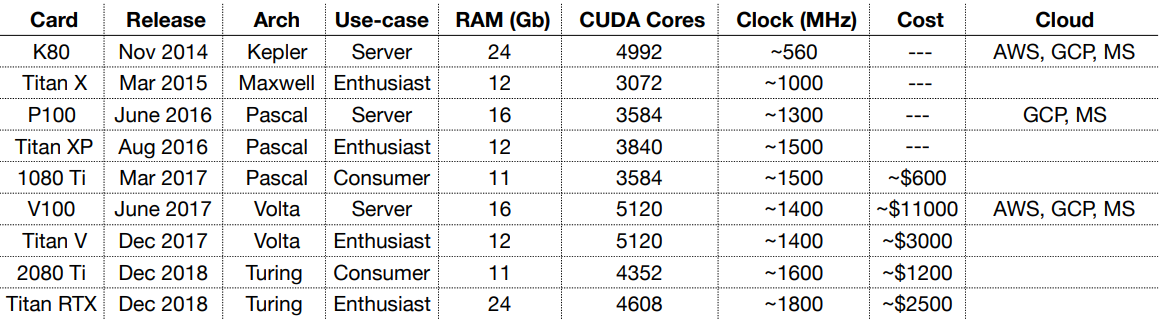
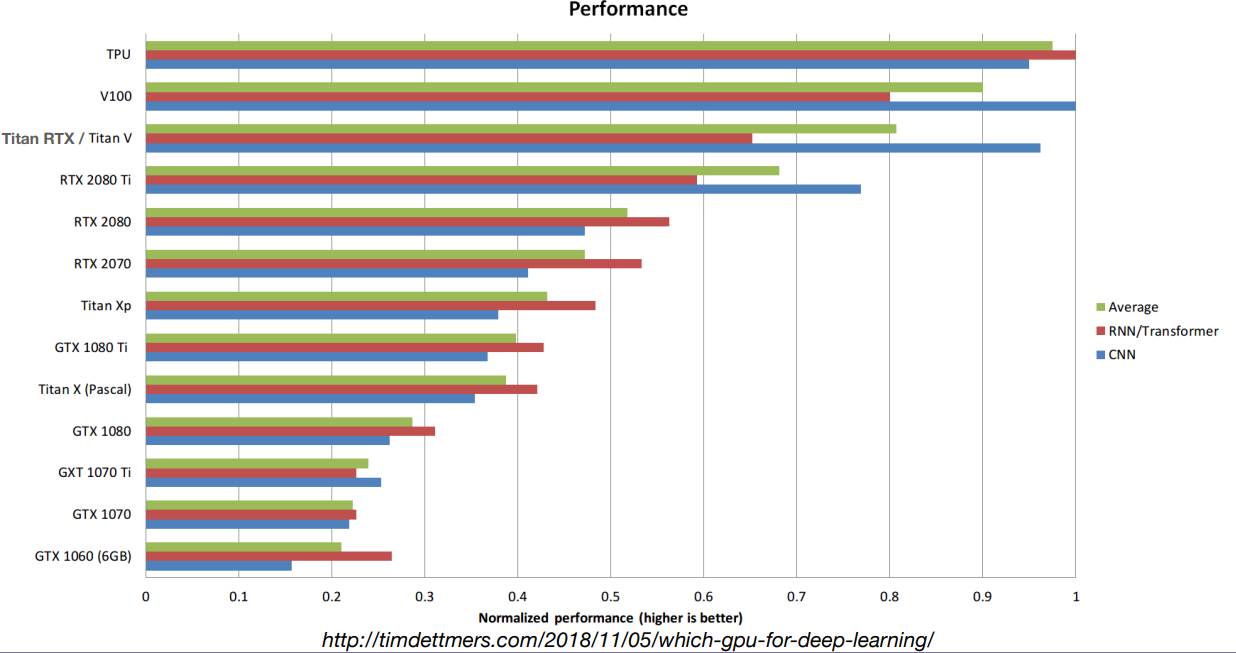
GPU Comparison Table
Performance
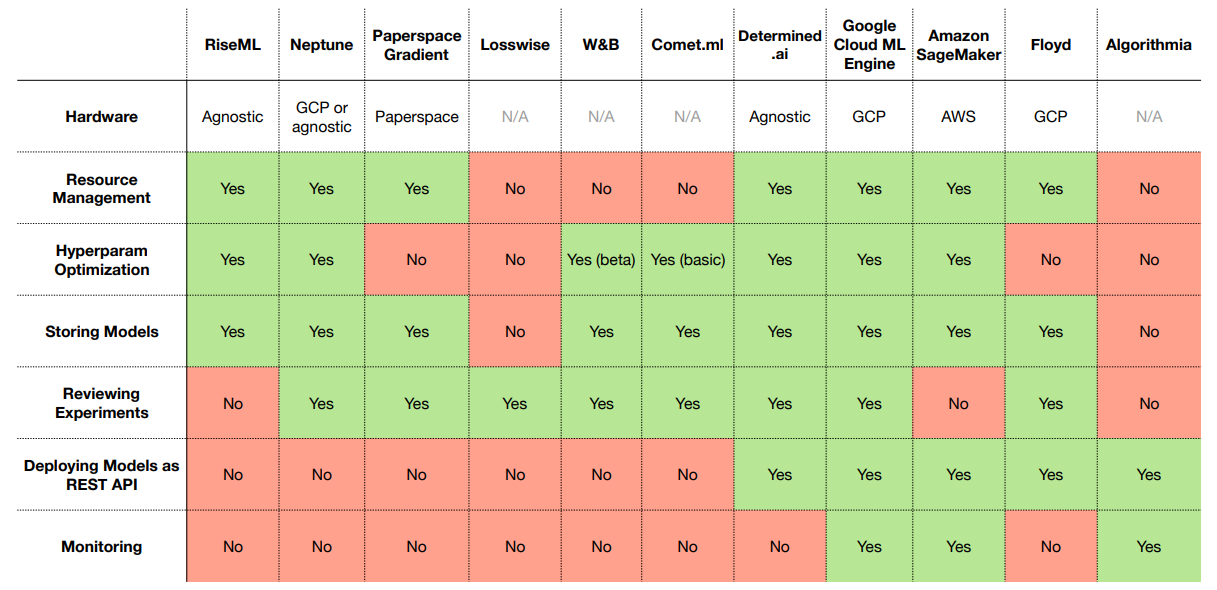
All-in-one Solutions
Data Management
- Most DL applications require lots of labeled data
- RL through self-play, GANs do not – but are not yet practical
- Publicly available datasets = No competitive advantage
- But can serve as starting point
- But can serve as starting point
Roadmap
Data Labeling
- User interfaces
- Sources of labor
- Service companies
Conclusions:
- Outsource to full-service company if you can afford it
- If not, then at least use existing software
- Hiring part-time makes more sense than trying to make crowd-sourcing work
Data Storage
- Building blocks
- Filesystem
- Object Storage
- Database
- “Data Lake”
- What goes where
- Binary data(images, sound files, compressed texts) is stored s objects
- Metadata(labels, user activity ) is sorted in database
- If need features which are not obtainable from database(logs), set up data lake and a process to aggregate needed data
- At training time, copy the data that is needed onto filesystem(local or networked)
Data Versioning
- Level 0: unversioned
- Level 1: versioned via snapshot at training time
- Level 2: versioned as a mix of assets and code
- Level 3; Specialized data versioning solution
Data Workflows

ML Teams
- The AI talent gap
- ML-Related roles
- ML team structures
- The hiring process
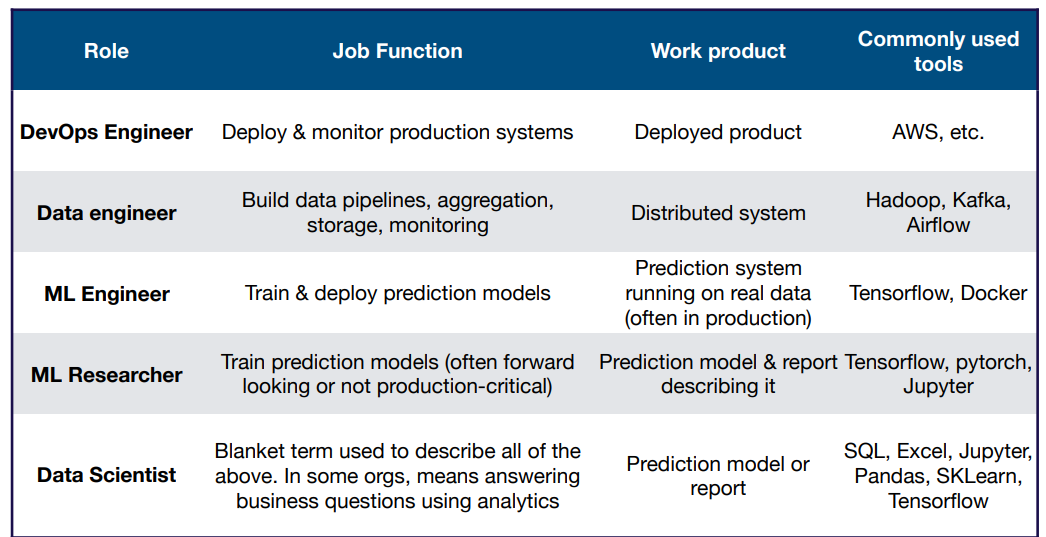
Breakdown of Job Function by Role
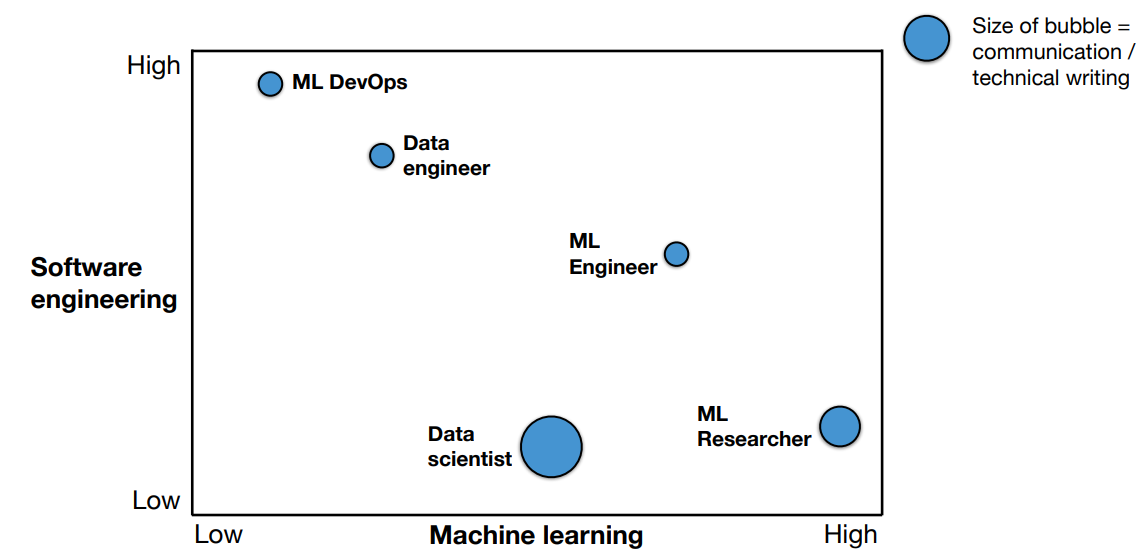
What Skills are needed for the Roles
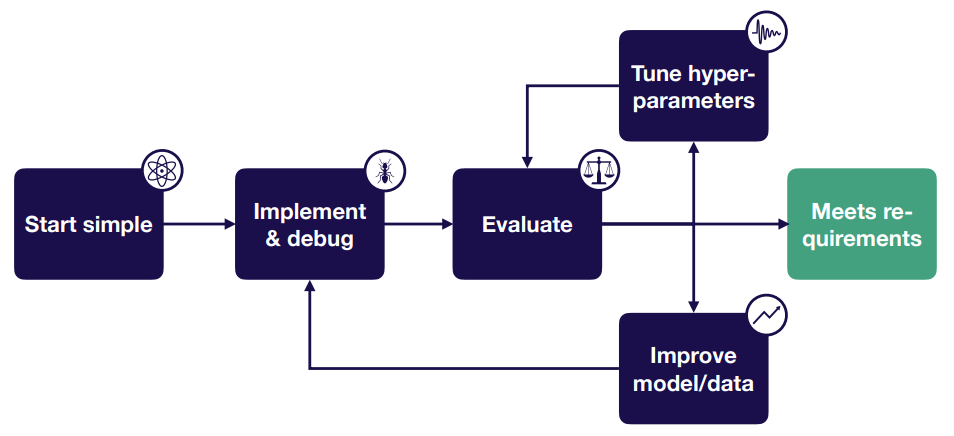
Troubleshooting Deep Neural Networks
Why is your performance worse?
- Implementation bugs
- Hyperparameter choices
- Data / model fit
- Dataset construction
- Not enough data
- class imbalance
- noisy labels
- train/test from different distributions
- etc
Learning rate is sensitive.
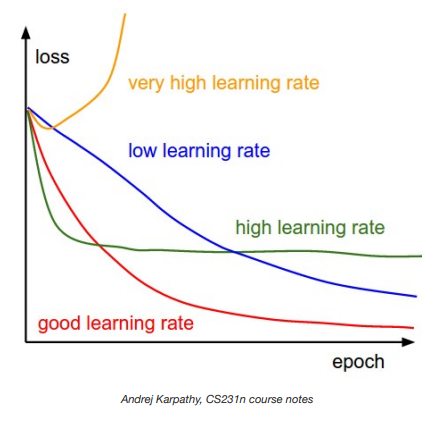
Strategy for DL Troubleshooting
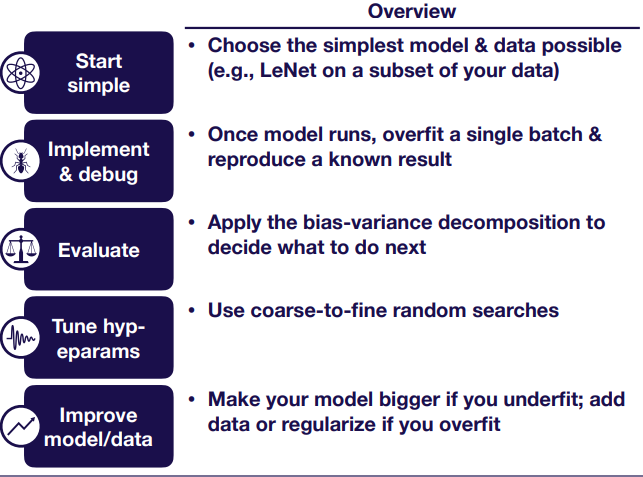
Quick Summary
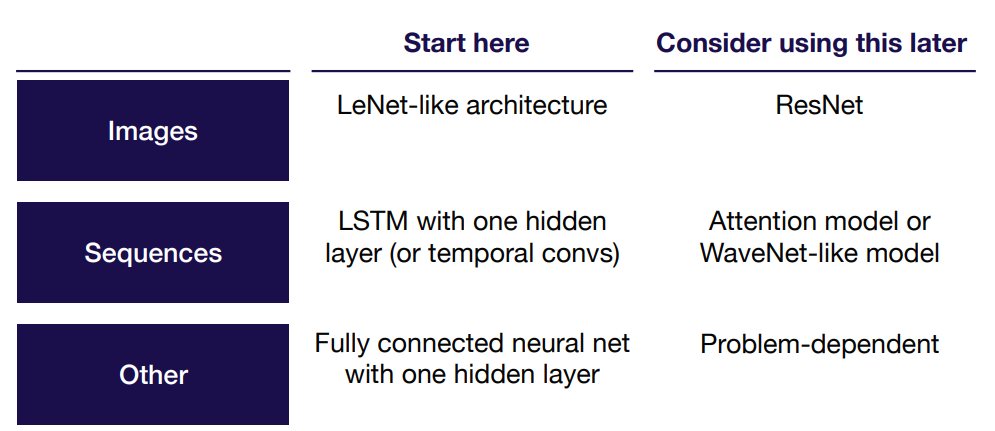
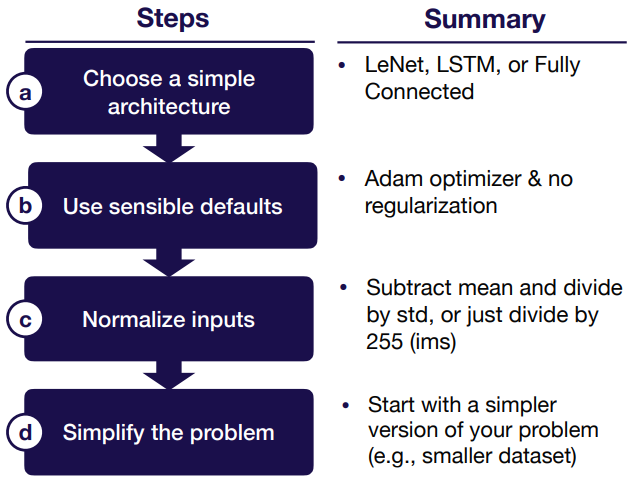
Starting Simple
- Choose a simple architecture
- Use sensible defaults
- Normalize inputs
- Simplify the problem
Choose a Simple Architecture
Architecture Selection:
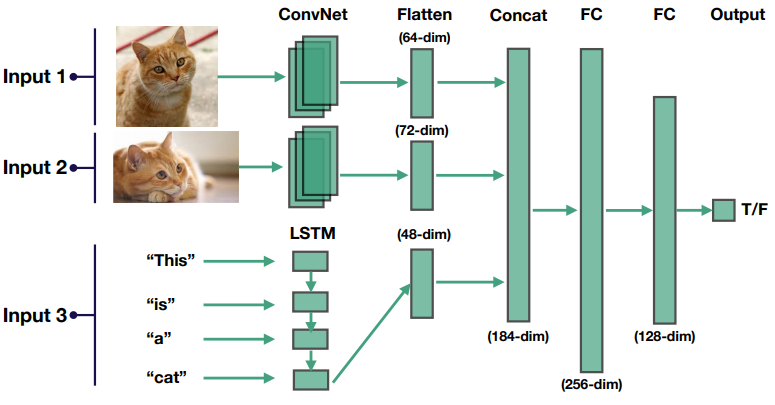
Dealing with multiple input modalities:
- Map each into a lower dimensional feature space
- Concatenate
- Pass through fully connected layers to output
Use Sensible Defaults
- Optimizer: Adam optimizer with learning rate 3e-4
- Activations: Relu(FC and Conv models), tanh(LSTMs)
- Initialization: He et al. Normal(relu), Glorot normal(tanh)
- Regularization: None
- Data normalization: None
Definitions of recommended initializers:

Normalize Inputs
- Subtract mean and divide by variance
- For images, fine to scale values to [0,1] or -0.5, 0.5. Be careful, make sure your library doesn’t do it for you!
Simplify the Problem
- Start with a small training set(?10, 000 examples)
- Use a fixed number of objects, classes, image size, etc
- Create a simpler synthetic training set
Summary for Starting Simple
Implement & Debug
The Five most Common DL Bugs

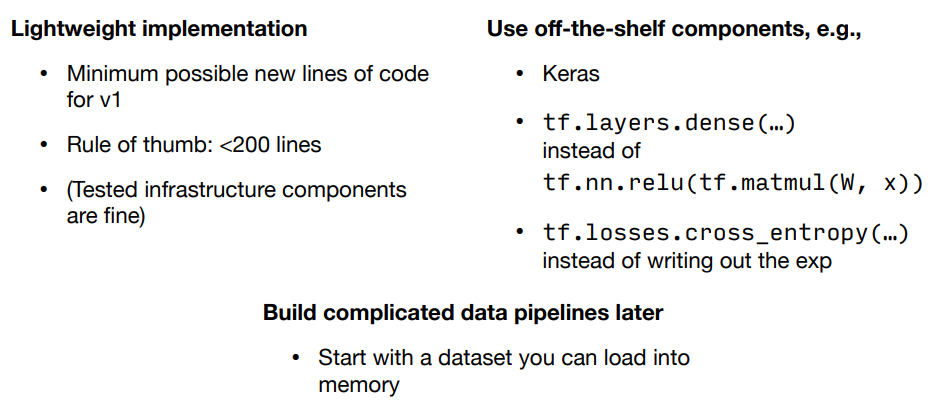
General advice for implementing your model:
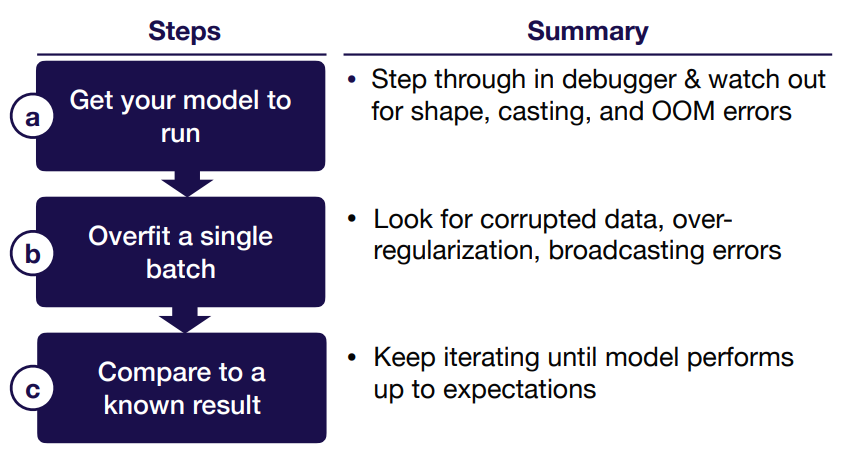
Get Your Model to Run
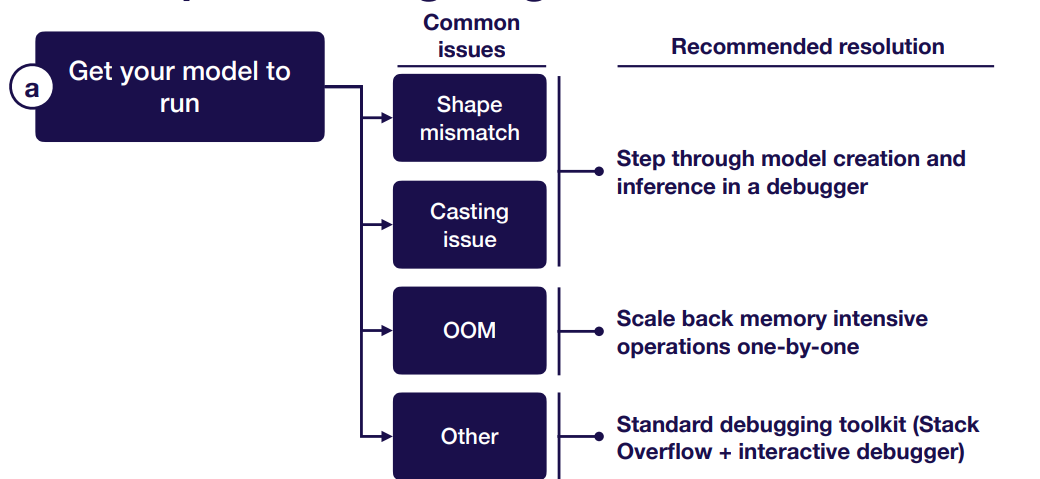
Shape mismatch:
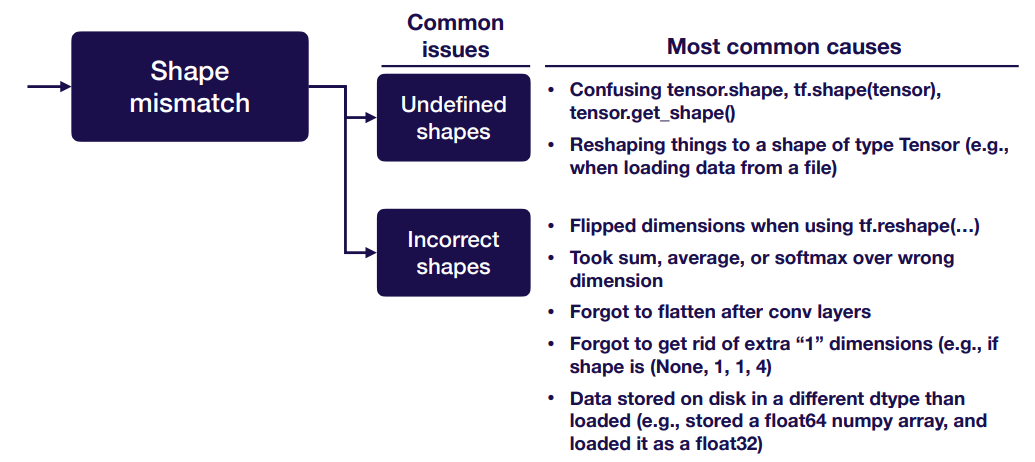
Casting issue: Common issue is data not in float32, the most common causes are:
- Forgot to cast images from uint8 to float32
- Generated data using numpy in float64, forgot to cast to float32
OOM:
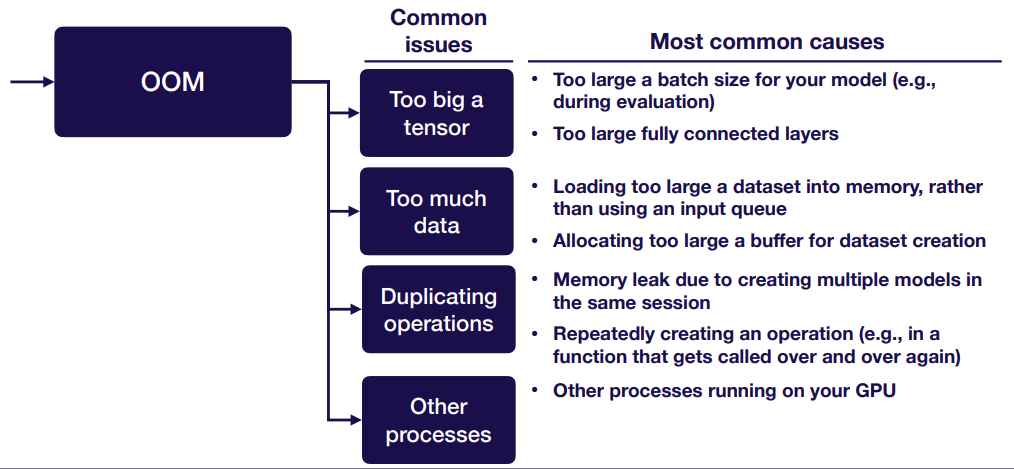
Other common errors:
- Forgot to initialize variables
- Forgot to turn off bias when using batch norm
- “Fetch argument has invalid type”-usually you overwrote one of your ops with an output during training
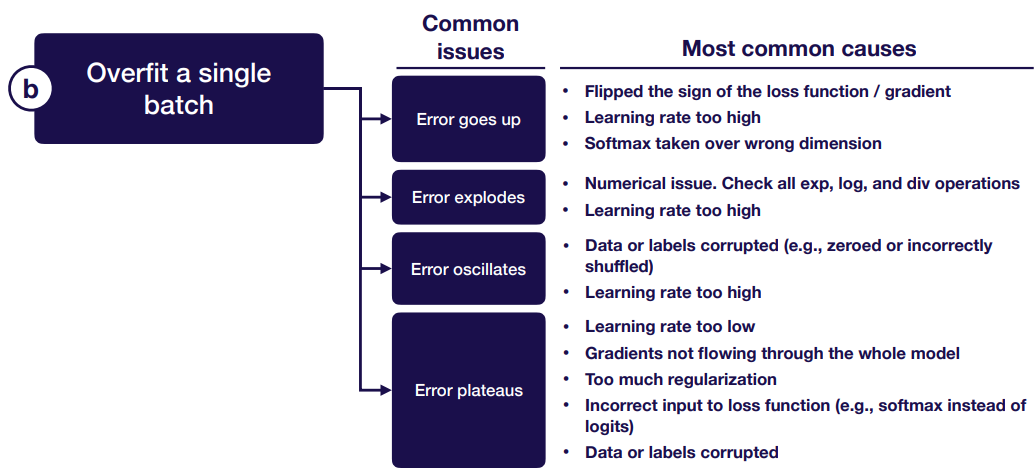
Overfit a Single Batch
Compare to a Known Result

Summary for Implement & Debug
Evaluate
Bias-variance Decomposition
Test error = irreducible error + bias + variance + val overfitting + distribution shift
This assumes train, val, and test all come from the same distribution.
Handling distribution shift

Improve Model/Data
Prioritizing improvements (i.e., applied b-v), steps:
- Address under-fitting
- Address over-fitting
- Address distribution shift
- Re-balance datasets(if applicable)
Address Under-fitting (i.e., Reducing Bias)

Address Over-fitting (i.e., Reducing Variance)

Address Distribution Shift

Error analysis for pedestrian detection problem:
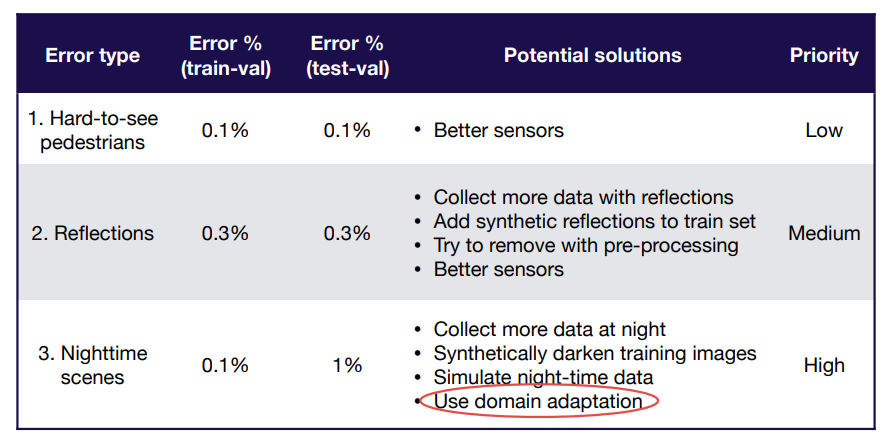
Domain Adaptation
Domain adaptation is a techniques to train on “source” distribution and generalize to another “target” suing only unlabeled data or limited labeled data.
When should you consider using it?
- Access to labeled data from test distribution is limited
- Access to relatively similar data is plentiful
Types of domain adaption:
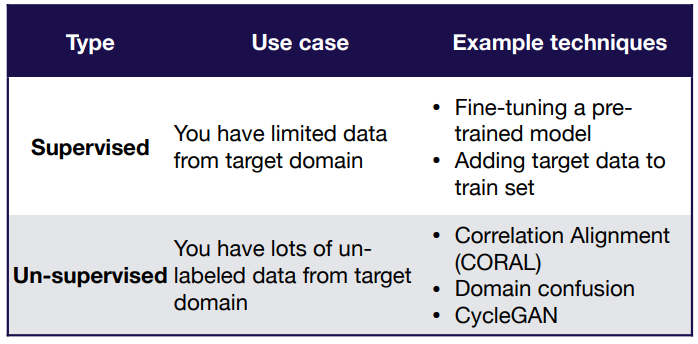
Re-balance Datasets(If Applicable)
If test-val looks significantly better than test, you overfit to the val set due to small val sets or lots of hyper parameter tuning. The solution is to recollect val data.
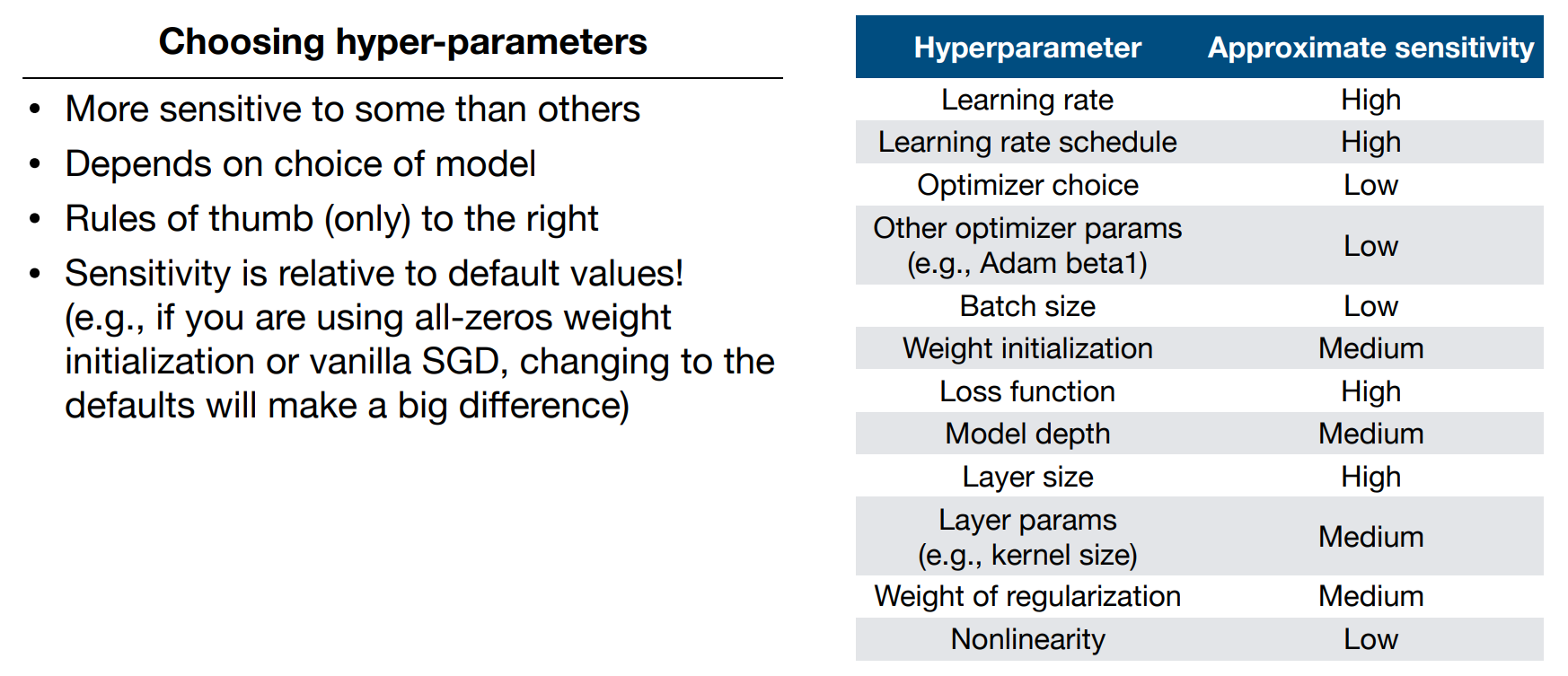
Tune Hyper-parameters
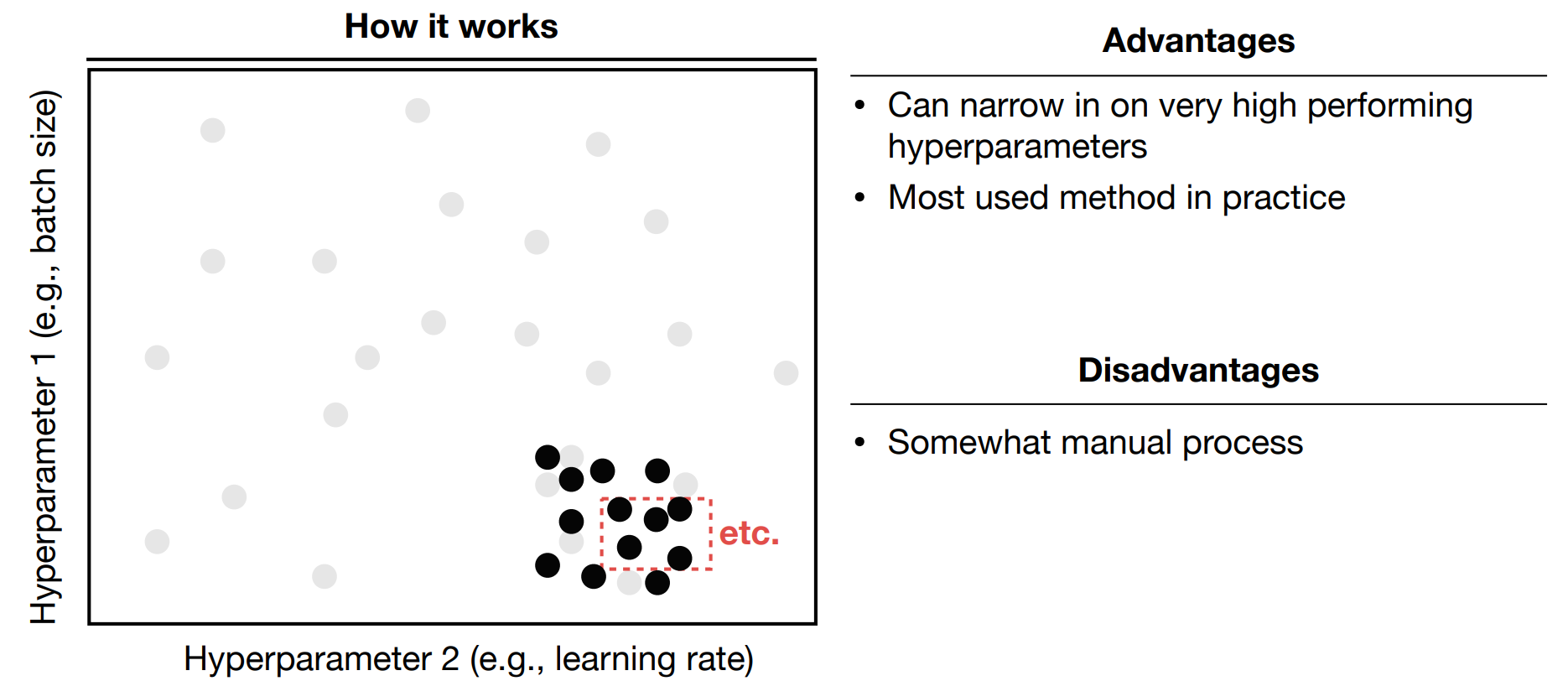
- Coarse-to-fine random searches
- Consider Bayesian hyper-parameter optimization solutions as your codebase matures
Manual Hyperparameter Optimization
- For a skilled practitioner, may require least computation to get good result.
- Requires detailed understanding of the algorithm
- Time-consuming
Grid Search
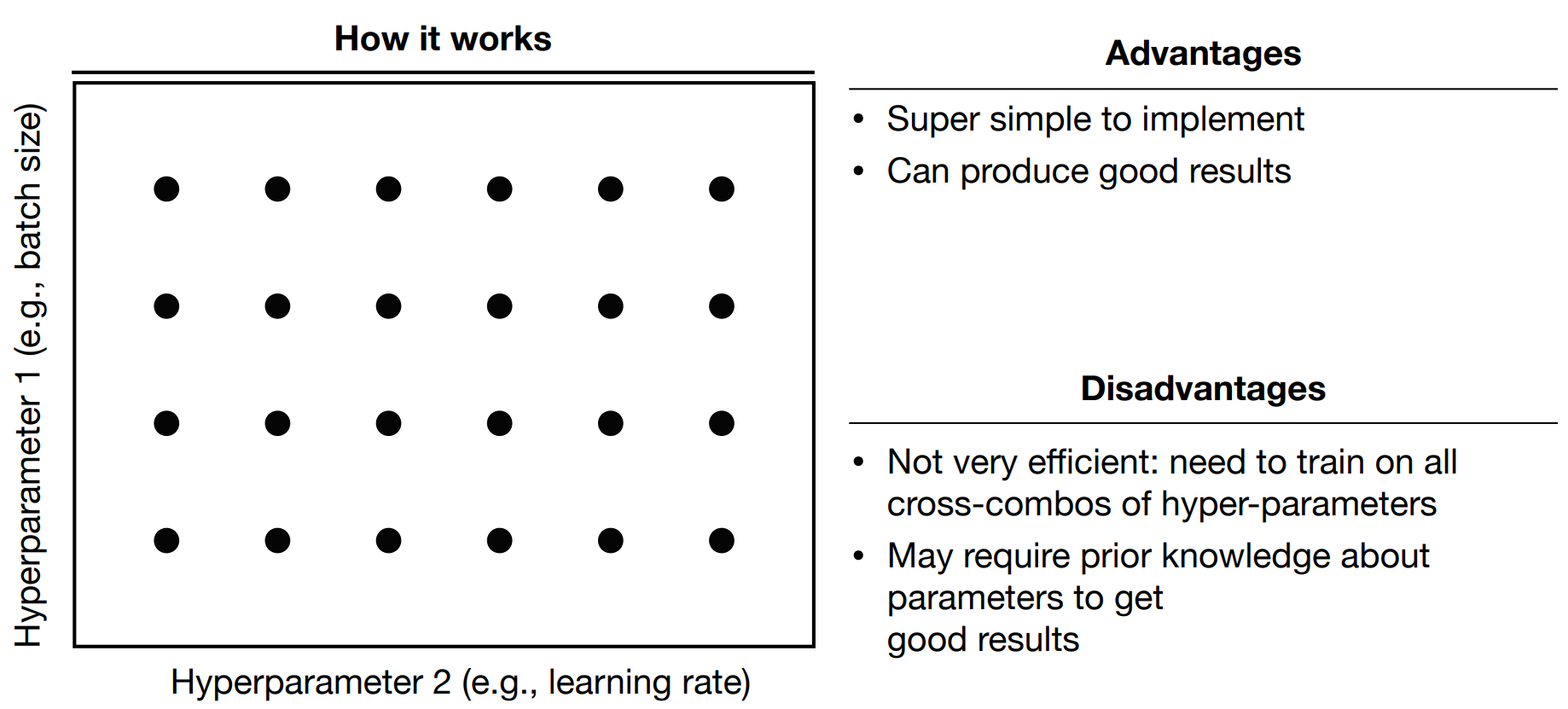
Random Search
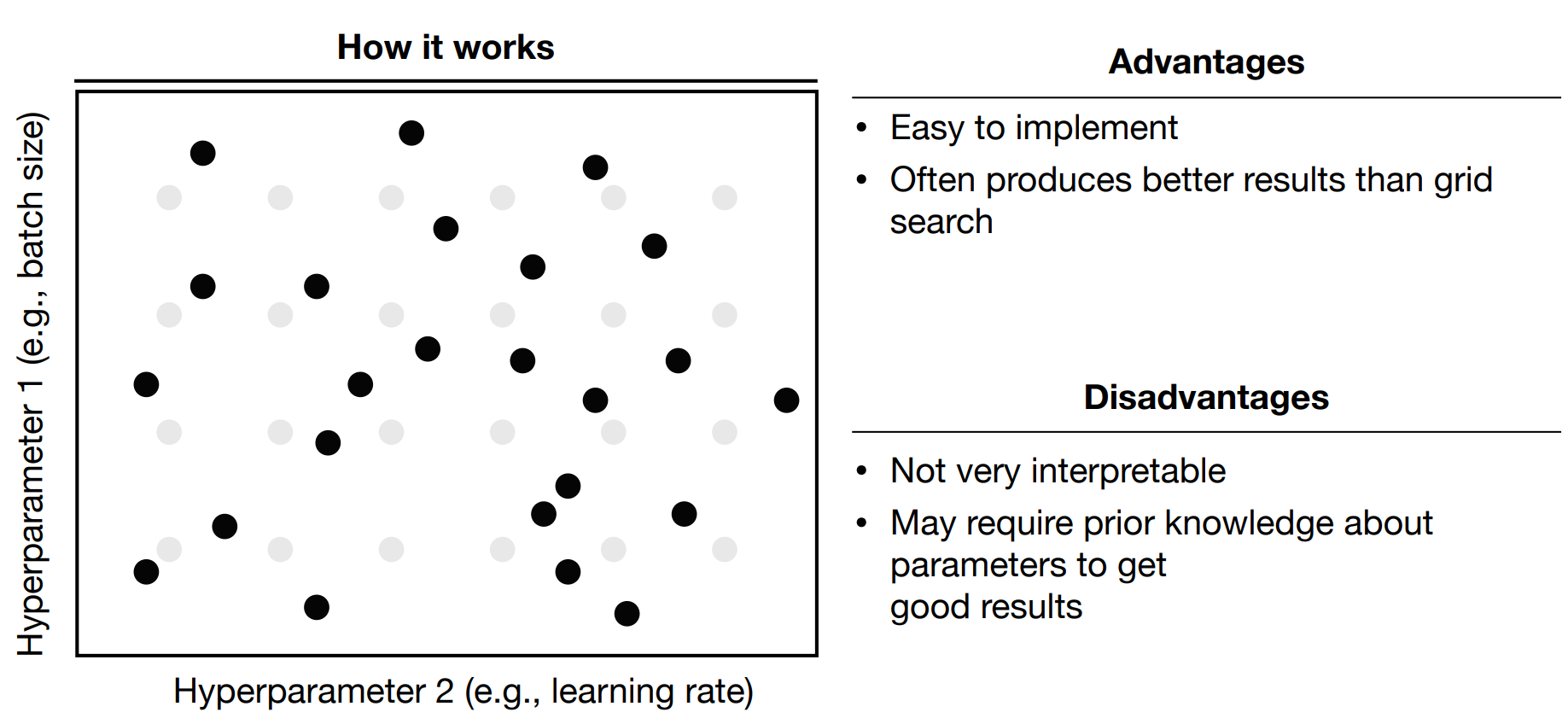
Coarse-to-fine
Bayesian Hyperparameter Optimization

Testing & Deployment
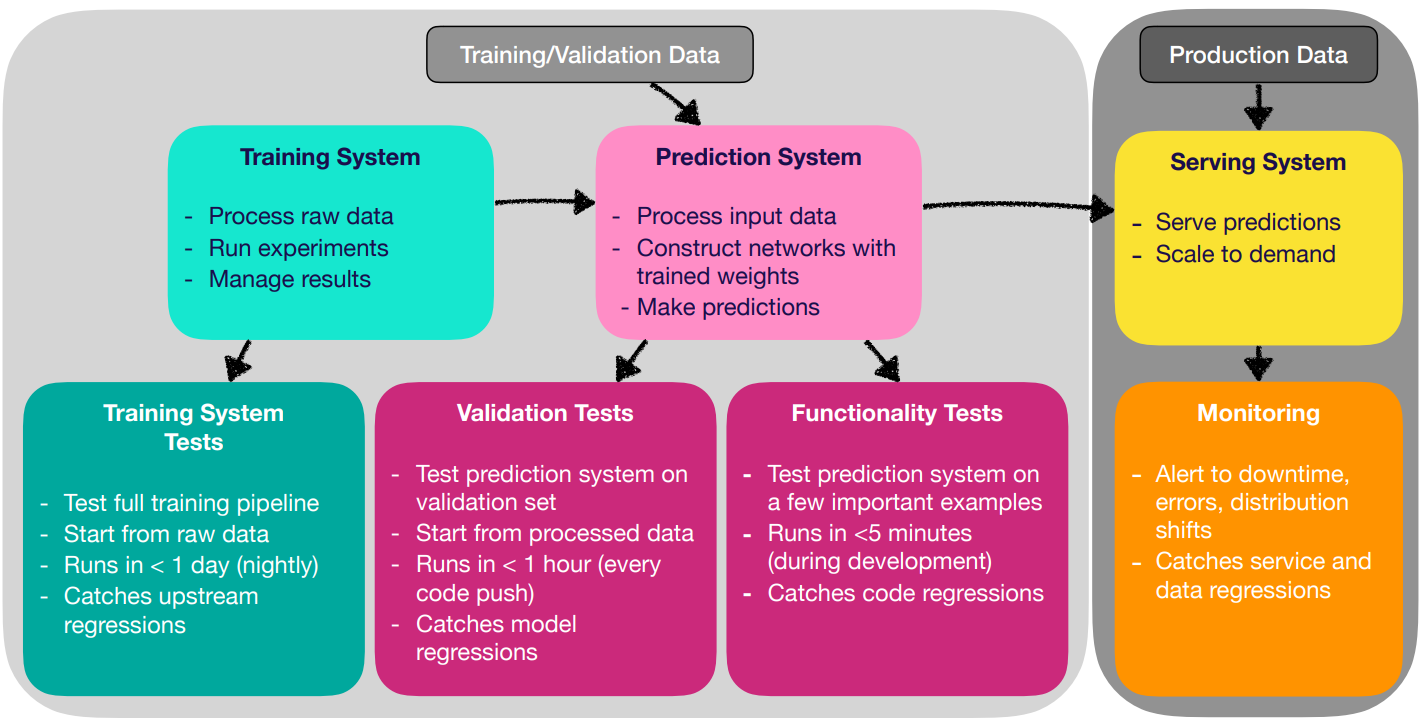
Different tests:
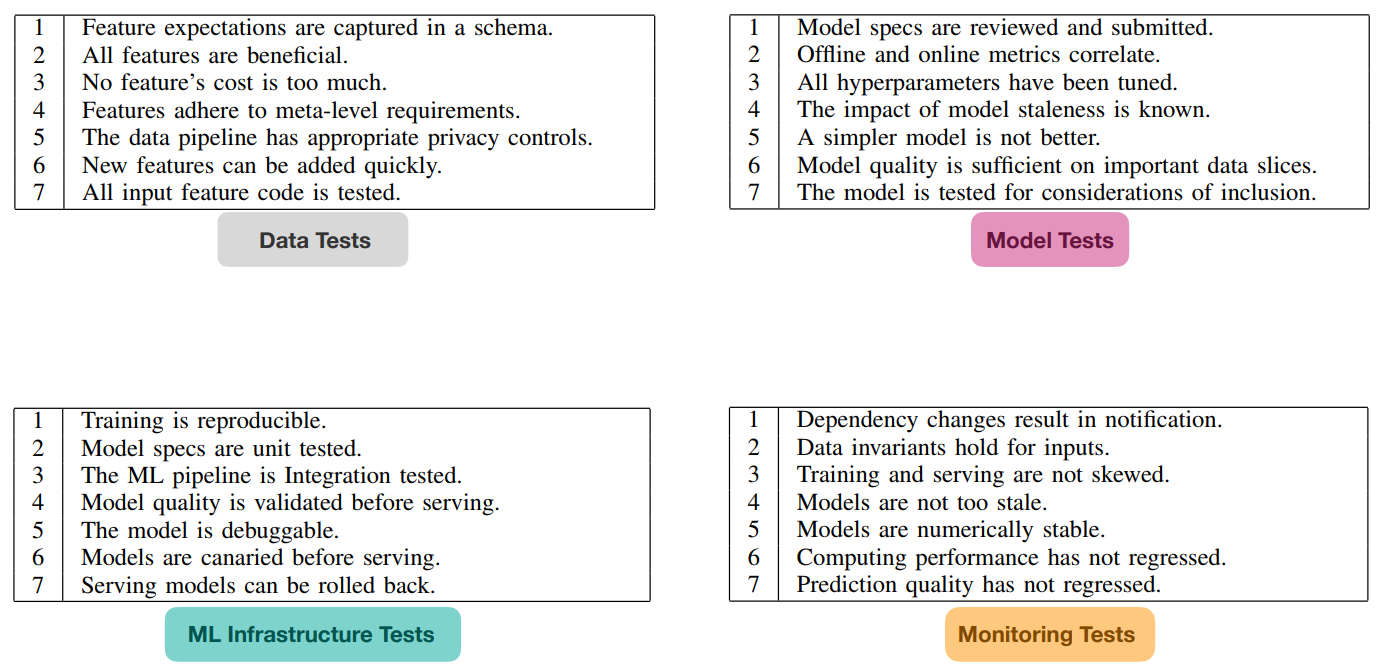
Scoring the Test

Testing / CI
- Unit / Integration Tests
- Tests for individual module functionality and for the whole system
- Continuous Integration
- Tests are run every time new code is pushed to the repository, before updated model is deployed
- SaaS for CI
- CircleCI, Travis, Jenkins, Buildkite
- Containerization(via Docker)
Web Deployment
- REST API
- Serving predictions in response to canonically-formatted HTTP requests
- The web server is running and calling the prediction system
- Options
- Deploying code to VMs, scale by adding instances
- Deploy code as containers, scale via orchestration
- Deploy code as a “serverless function”
Deploying Code to Cloud Instances
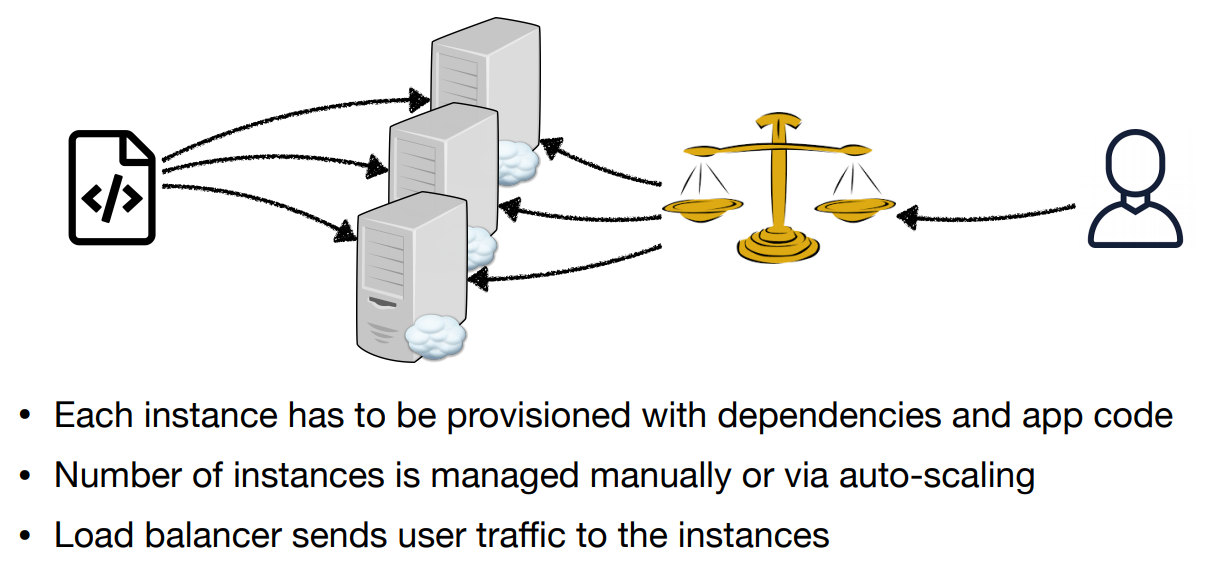
Cons:
- Provisioning can be brittle
- Paying for instances even when not using them (auto-scaling does help)
Deploying containers
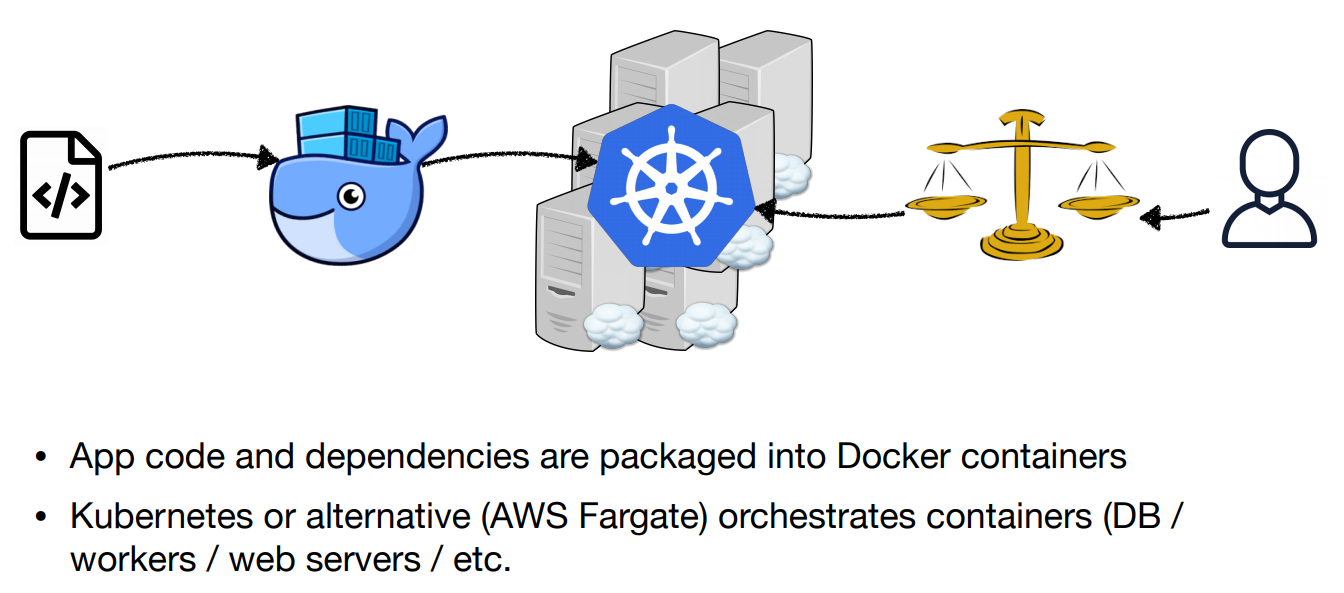
Cons: - Still managing your own servers and paying for uptime, not compute-time
Deploying Code as Serverless Functions
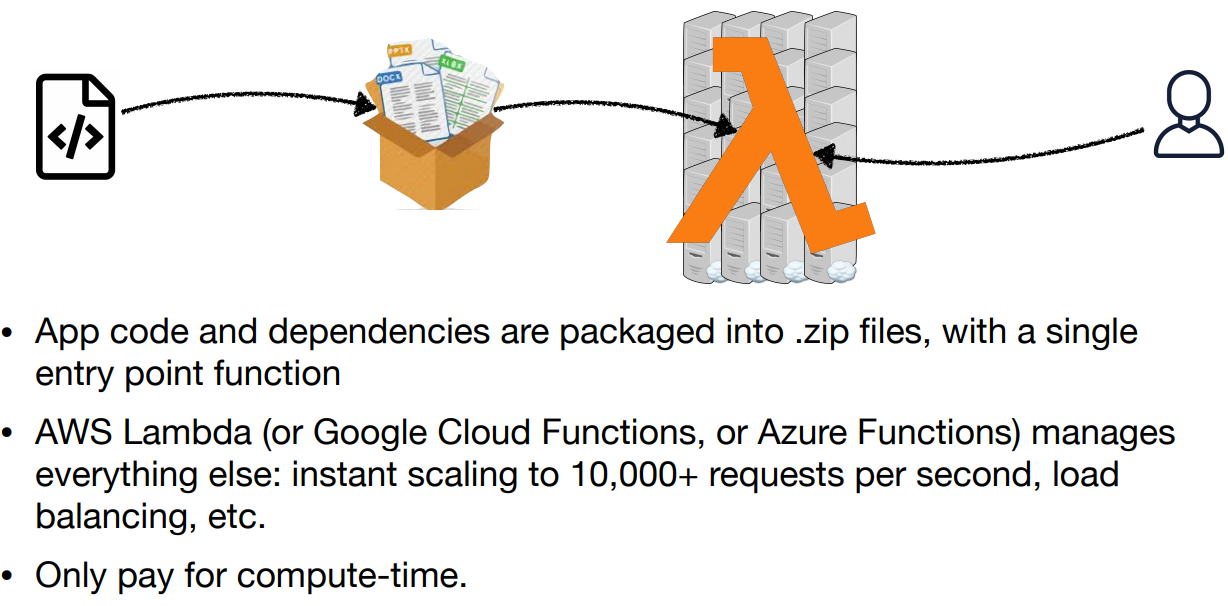
Cons:
- Entire deployment package has to fit within 500MB, <5 min execution, <3GB memory (on AWS Lambda)
- Only CPU execution
Model Serving
Web deployment options specialized for machine learning models
- Tensorflow Serving (Google)
- Model Server for MXNet (Amazon)
- Clipper (Berkeley RISE Lab)
- SaaS solutions like Algorithmia
Note:
- If you are doing CPU inference, can get away with scaling by launching more servers, or going serverless
- If using GPU inference, things like TF serving and Clipper become useful by adaptive batching, etc
Hardware / Mobile
Problems:
- Embedded and mobile devices have little memory and slow/expensive compute
- Have to reduce network size / use tricks / quantize weights
- Mobile deep learning frameworks have less features than full versions
- Have to adjust network architecture
Methods for Compression
- Parameter pruning
- Can remove correlated weights; can add sparsity constraints in training
- Introduce structure to convolution
- Knowledge distillation
- Train a deep net on the data, then train a shallow net on the deep net
MobileNets
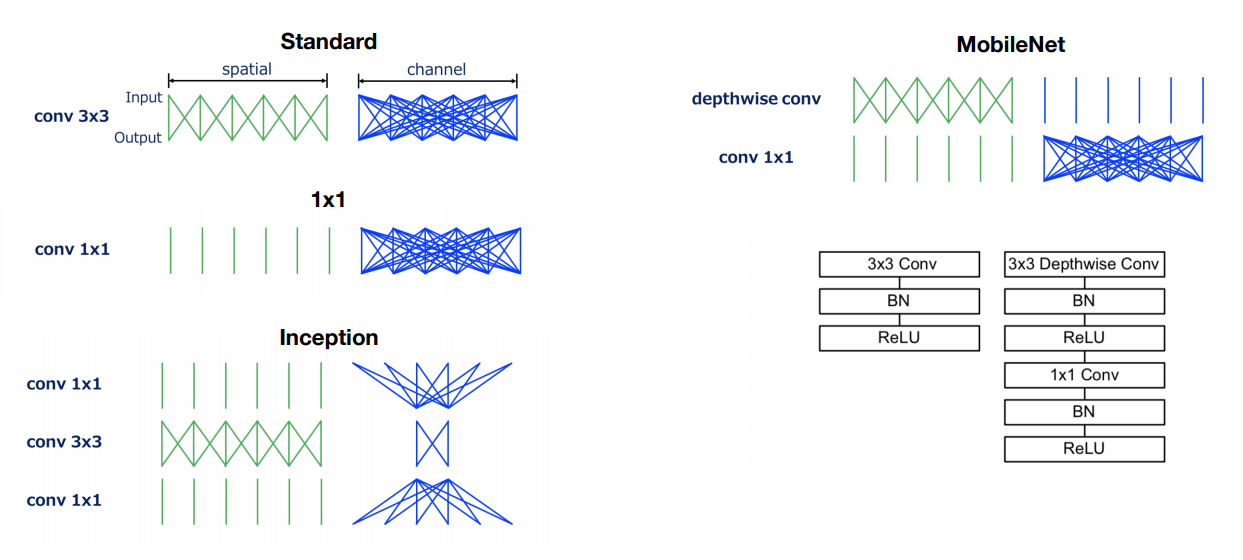
Tensorflow Options
- Tensorflow Lite
- More recent solution - usually smaller, faster, and has less dependencies
- Only a limited set of operators - not all models will work
- Tensorflow Mobile
- Has a fuller(but not full!) set of operators
Note: Cover Picture