跳表 Skip List
跳表是一种各方面性能都比较优秀的动态数据结构,利用了空间换时间的设计思路,通过多级索引来提高查询效率,实现了基于链表的“二分查找”,跳表是一种动态数据结构,支持快速的插入、删除、查找操作,时间复杂度都是O(logn),但是其空间复杂度是O(n)。
对于单链表来说,查找某个数据,需要遍历整个链表,时间复杂度是O(n),改进方法是每两个结点去一个结点到上一级,我们把抽出来的那一级叫做索引或者索引层,示意图如下:
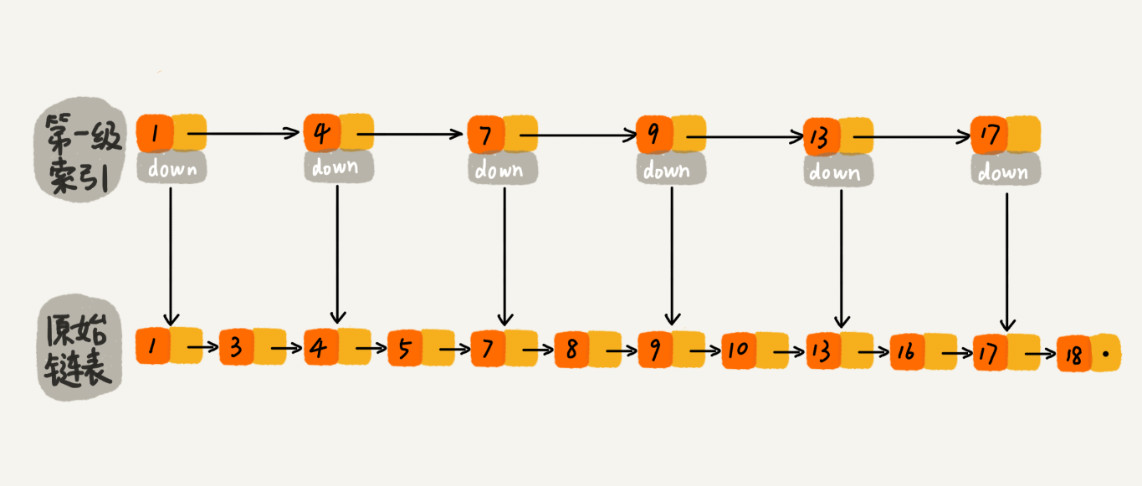
图中的down表示down指针,指向下一级结点。我们先在索引层中查找,如查找16,当找到13时,发现下一个结点是17,通过down指针下降到原始链表13,然后继续查找即可。这样查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。
在第一级索引的基础上在每两个结点抽出一个结点到第二级索引,这样遍历的结点数量就又减少了。示意图如下:
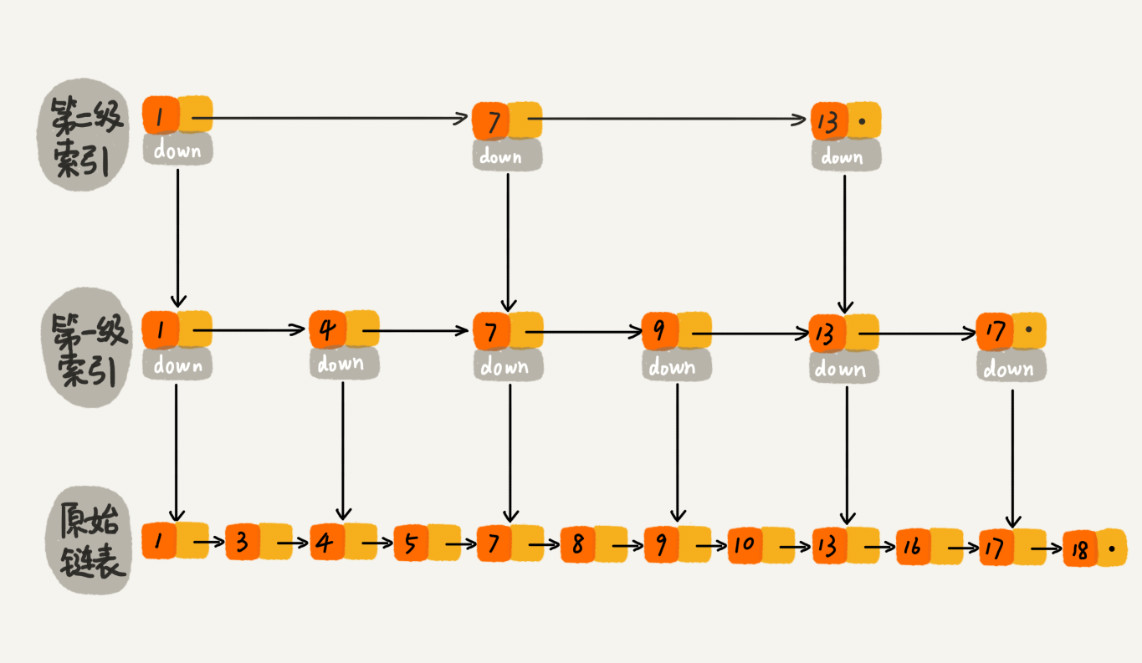
当数据量比较大的是否,在构建索引之后,查找效率的提升就会非常明显。
链表加多级索引的结构,就是跳表,跳表可以明显提高查询效率。
跳表中第k级索引的结点个数是第k-1即索引的结点个数的1/2,那么第k即索引结点的个数就是n/(2^k)。每一级索引都最多只需要遍历3个结点,示意图如下:
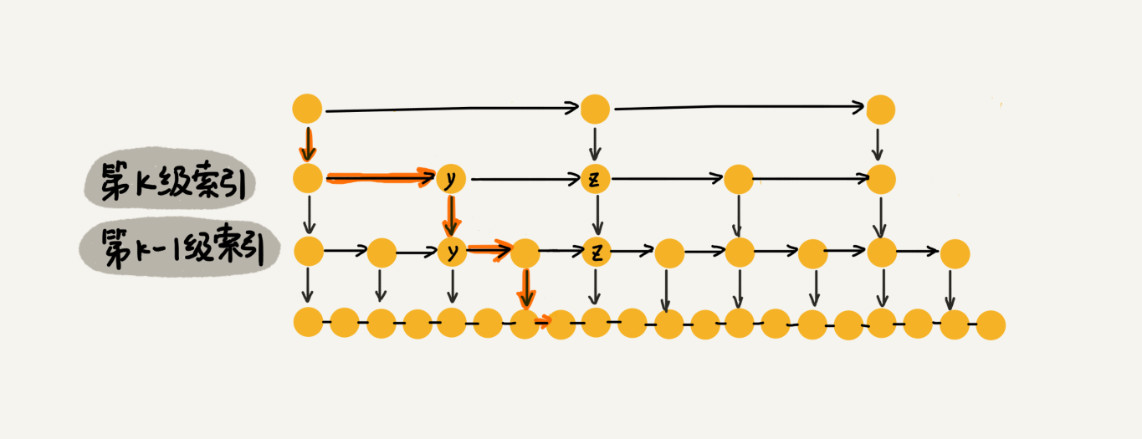
在跳表中查询任意数据的时间复杂度就是O(logn),但是建立索引消耗了更多的内存空间,这是空间换时间的设计思路。
当每隔两个结点提取一个到上一级索引的情况,跳表的空间复杂度是n/2+n/4+n/8+…+8+4+2=n-2,所以跳表的空间复杂度是O(n),示意图如下:

如果每隔三个结点提取一个到上一级索引的情况,跳表的空间复杂度是n/3+n/9+n/27+…+9+3+1=n/2,比上面的少了一半的空间复杂度。
在实际的软件开发过程中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
高效的动态插入和删除
跳表支持动态的插入、删除操作,且时间复杂度都是O(logn)。
跳表的插入操作如下:
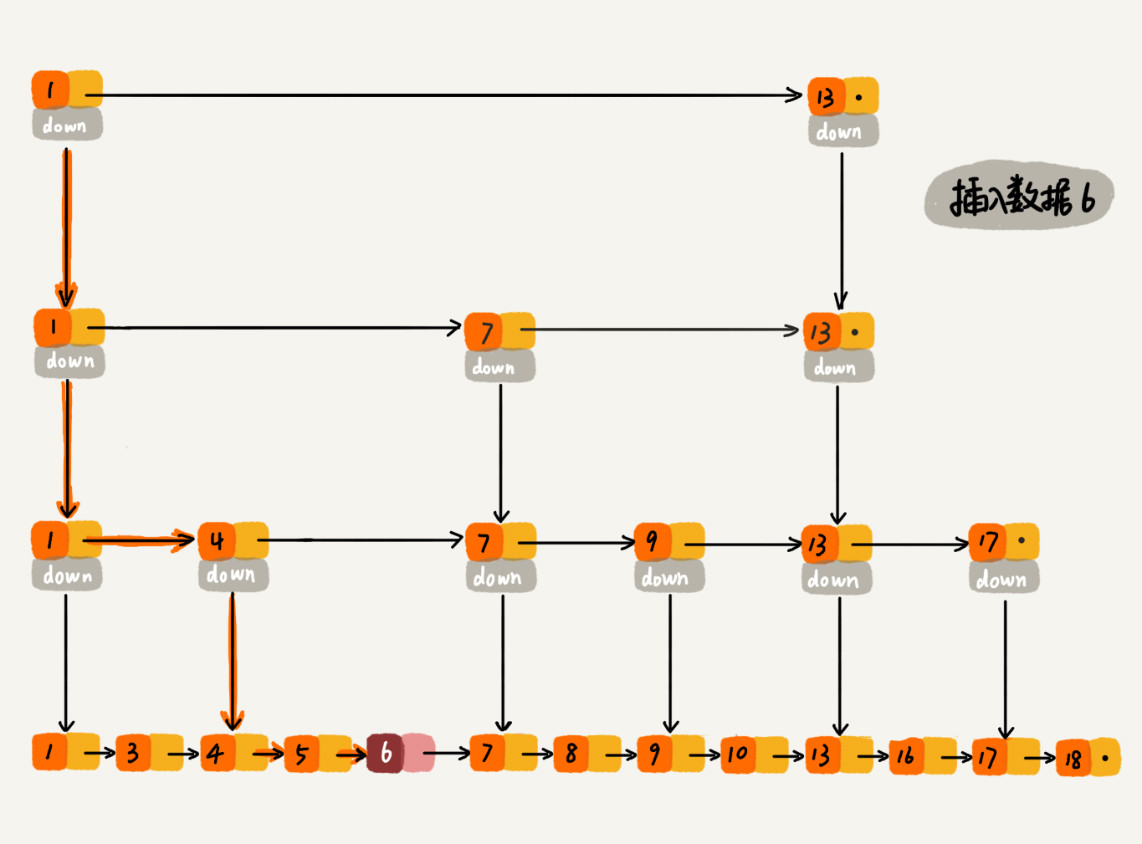
跳表的删除操作,如果一个结点在索引中也出现,我们除了要删除原始链表中的结点,还要删除索引中的结点,单独的删除只需要O(1)时间复杂度,查找需要O(logn),最终删除也是O(logn)的时间复杂度。
跳表索引动态更新
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某2个索引结点之间数据非常多的情况,极端情况下,跳表还会退化成单链表,示意图如下:
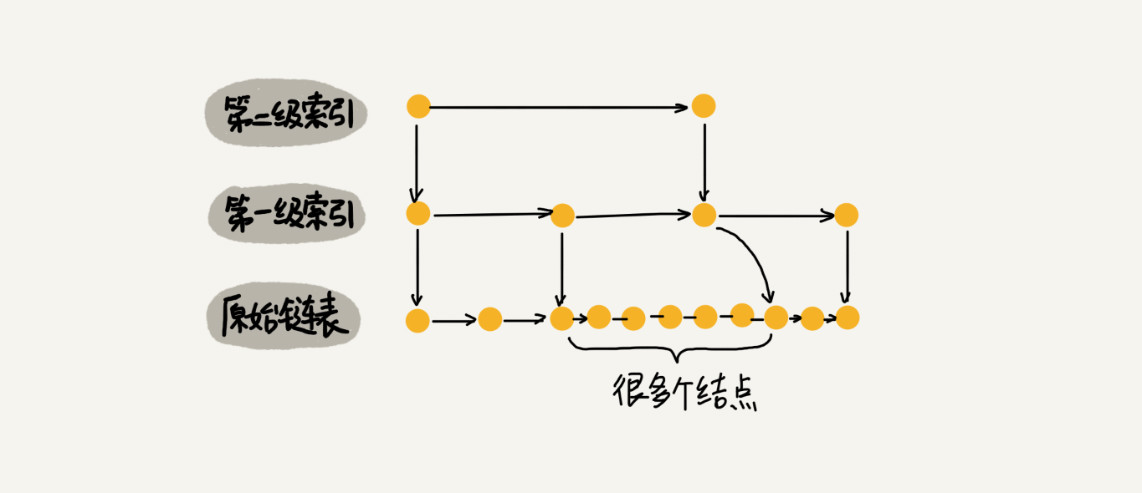
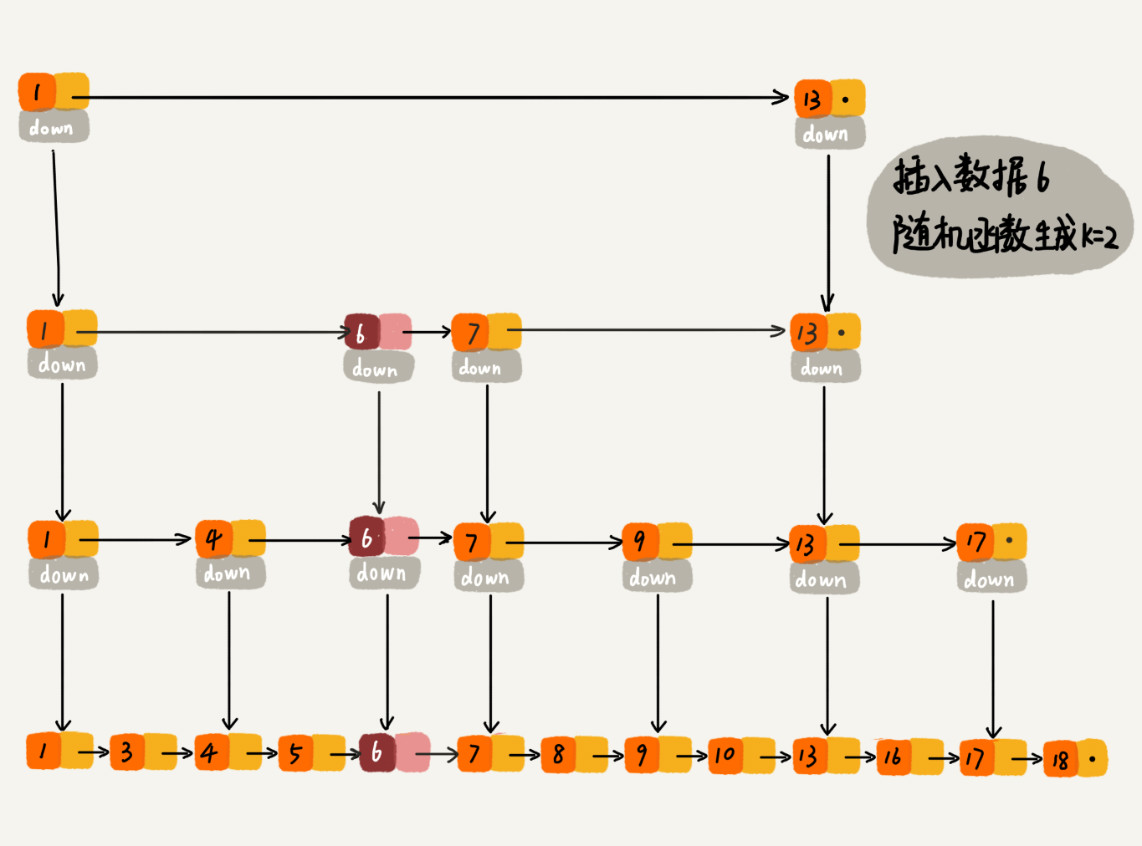
跳表是通过随机函数来维护整个数据的平衡性。在往跳表中插入数据时,可以通过随机函数生成一个值K,然后将整个结点添加到第一级到第K级这K级索引中,示意图如下:
为什么redis中要用跳表来实现有序集合,而不是红黑树
Redis中的有序集合支持的核心操作主要有下面几个:
- 插入一个数据
- 删除一个数据
- 查找一个数据
- 迭代输出有序序列
- 按照区间查找数据,如查找值在[100,200]之间的数据
跳表的前四个操作和红黑树的时间复杂度都是一样的O(logn),但是按照区间查找数据的操作,红黑树的效率没有跳表高。跳表可以做到O(logn)的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了,这样做非常高效。
另一个原因,相比于红黑树,跳表更容易实现。跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
注:本文是《数据结构与算法之美》的读书笔记,配套代码地址GitHub。本文仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture