模型融合
推荐系统在技术实现上一般划分为三个阶段:挖掘、召回、排序
挖掘阶段:对用户和物品做非常深入的结构化分析,并且建立好索引,供召回阶段使用,大部分挖掘工作都是离线进行的。
召回阶段:各种简单的、复杂的推荐算法,比如说基于内容的推荐,基于物品的协同过滤都会产生一些推荐结果,每种算法都会产生一批推荐结果,一般还同时附带给每个结果产生一个推荐分数,由各算法得出。
排序阶段:对召回阶段产生的推荐分数排序,但是不能依据各自的分数,原因如下:
- 有的算法如决策树可能只给结果,没有分数
- 每种算法给出的分数范围不一样,不能直接互相比较
- 即使强行把所有分数都归一化,依然不能互相比较,因为产生的机制不同,有的可能普遍偏高,有的可能普遍偏低
不同的算法只负责推举出候选结果,真正最终是否推荐给用户,由另一个统一的模型说了算,这个就叫做模型融合。
模型融合的作用除了统一各个算法结果外,还有集中提升效果的作用,在机器学习中,有专门为融合而生的集成学习思想。
逻辑回归和梯度提升决策树组合
我们将逻辑回归和梯度提升决策树组合叫做“辑度组合”。
辑度组合原理
逻辑回归
CTR预估就是在推荐一个物品之前,预估一下用户点击它的概率有多大,再根据这个预估的点击率对物品排序输出。
逻辑回归是广义线性模型,相比于传统线性模型,在线性模型基础上增加了Sigmoid函数,很多非线性关系它无能为力。它需要特征和权重来计算点击率。
- 特征: x 就是用量化、向量的方式把一个用户和一个物品的成对组合表示出来。量化方式包括两种:实数和布尔。类别形式的字段不能直接参与计算。
- 权重: w 每个特征对应一个权重,需要模型自主从大量的历史数据中学习得到。
有了特征x和权重w,利用点积计算,得到一个传统线性模型的输出,再使用sigmoid函数对值做一个变换,得到[0,1]之间的输出值,也就是预估的CTR。Sigmoid函数公式如下:
$$ \sigma (w \times x) = \frac{1}{1+e^{-(w \times x)}} $$
逻辑回归要求取值都在[0,1]之间。
特征组合的难点在于:组合数目非常庞大,而且并不是所有组合都有效,只有少数组合有效。
特征工程 + 线性模型,是模型融合、CTR预估等居家旅行必备。
梯度提升决策树 GBDT
树模型最原始的是决策树,简称DT。把多个表现略好于随机乱猜的模型以某种方式集成在一起的集成树模型,有随机森林,简称RF,和梯度提升决策树,简称GBDT。
GBDT起到的作用就是对原始的特征做各种有效的组合,一棵树就是一种组合决策过程。
GBDT和Adaboost算法不同之处,GBDT的叶子节点都是被划分进去的样本年龄均值,因此可以用来做回归。GBDT用上一颗树去预测所有样本,得到每一个样本的残差,下一棵树不是去预测样本的目标值,而是去拟合上一棵树的残差。依次迭代,直到满足条件最终停止。
在得到所有这些树之后,真正使用时,是将它们的预测结果相加作为最终输出结果。
做回归时,GBDT损失函数为误差平方和,做分类时,损失函数为适合分类的损失函数,如对数损失函数。更新时,上面的误差平方和的梯度就刚好是残差。对于CTR预估这样的二分类任务,可以将损失函数定义为:
$$ loss = -y\log(p) - (1-y)\log(1-p) $$
为了防止过拟合,需要添加正则化项,一般是:限定总的树个数、树的深度、以及叶子节点的权重大小。
构建每一棵树时如果遇到实数值的特征,还需要将起分裂成若干个区间,分裂指标有很多,如xgboost中的计算分裂点收益,也可以参考决策树所用的信息增益。
二者结合
Facebook在其广告系统中的方法是,将逻辑回归和梯度提升决策树结合在一起,GBDT的任务就是产生高阶特征组合。
具体做法: GBDT产生N棵树,一条样本来了之后,在每一颗树上都会从根节点走到叶子节点,到了叶子节点后,就是1或者0,把每一棵树的输出看成是一个组合特征,取值为0或者1,一共N棵树就会产生N个新的特征,这N个新的特征作为LR模型的输入,输出就是最终的结果。
因子分解机 Factorization Machine
对逻辑回归最朴素的特征组合就是二阶笛卡尔乘机,但是特征组合存在如下问题:
- 两两组合导致特征维度灾难
- 组合后的特征不见得都有效,事实上大部分可能无效
- 组合后的特征样本非常稀疏,意思就是组合容易,但是并不能在样本中找到对应的组合出现,也就没有办法在训练时更新参数。
包含了特征两两组合的逻辑回归线性部分预测函数如下:
$$ \hat{y} = \omega_0 + \sum_{i=1}^{n}\omega_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} \omega_{ij} x_i y_j $$
FM原理
因为逻辑回归在做特征组合时样本稀疏,从而无法学习到很多特征组合的权重,FM的思想就是对上面那个公式中的w_ij做解耦,让每一个特征学习一个隐因子向量V出来,预测函数如下:
$$ \hat{y} = \omega_0 + \sum_{i=1}^{n}\omega_i x_i + \sum_{i=1}^{n} \sum_{j=i+1}^{n} < V_i, V_j > x_i y_j $$
上面的公式和逻辑回归不同之处在于原来的w_ij变成两个隐因子向量的点积。一般实际使用中,因子分解机就使用到二阶特征组合就行了,高阶的计算复杂度会陡增。
模型训练
当做融合模型看,用来做CTR预估,预测目标是一个二分类,因子分解机的输出还需要经过Sigmoid函数变换:
$$ \sigma (\hat{y}) = \frac{1}{1+e^{-\hat{y}}} $$
因此,损失目标函数就是常用的Logistic Loss:
$$ loss(\theta) = - \frac{1}{m} \sum_{i=1}^{m} \left [ y^{(i)} \log{\sigma(\hat{y})} + (1 - y^{(i)}) \log{ (1 - \sigma(\hat{y}))} \right ] $$
因子分解机可以变为其他模型如:逻辑回归、SVD、SVD++、time-SVD。 因此因子分解机通常做模型融合,在推荐系统的排序阶段肩负起召回结果做从排序的任务。
FFM
在FM的基础上改进一下,改进思路是:不仅认为特征和特征之间有潜在关系,还认为特征和特征类型有潜在关系。
特征类型就是某些特征实际上是来自数据的同一个字段,比如用户ID,占据了很多维度,变成了很多特征,但他们都属于同一个类型,都叫用户ID。这个特征类型就是字段,即Field。这种改进叫做Field-aware Factorization Machines,简称FFM。
改进模型认为每个特征有f个隐因子向量,这里的f就是特征一共来自多少个字段,二阶组合部分改进后如下:
$$ \sum_{i=1}^{n} \sum_{j=i+1}^{n} < V_{i,fj}, V_{j,fi}> x_i y_j $$
FFM模型也常用来做CTR预估,在FM和FFM模型中,记得都要对样本和特征做归一化处理
深度和宽度兼具的模型
Google在2016年发表了Wide & Deep模型,主要分为两个部分:
- 线性部分
- 深度非线性部分
深宽模型,由逻辑回归作为最终输出单元,深模型最后一个隐藏层作为特征介入逻辑回归,宽模型的原始特征与之一起接入逻辑回归,然后训练参数。最终输出过程表示公式就是:
$$ P(Y=1|X) = \sigma (W_{wide}^T [X, \phi(X)] + W_{deep}^T a^{(lf)} + b) $$
Y是我们要预测的行为,二值变量,如购买,或点积,Google的引用场景为“是否安装APP”,sigma是sigmoid函数,W_wide是宽模型的权重,phi(X)是宽模型的组合特征,W_depp是深模型输出上的权重,a^{lf}是深模型的最后一层输出,b是线性模型的偏置。
技巧
- 数据生成,字符串形式的特征映射为ID,需要过滤掉出现样本较少的特征,对连续值做归一化。
- 模型训练,深度模型侧:
- 每个类别特征embedding成一个32为向量
- 将所有类别特征的embedding变量连成一个1200维左右的大向量
- 1200维度向量就送进三层以Relu作为激活函数的隐藏层
- 最终从Logistic Regression输出 宽模型侧就是特征交叉组合,为了提高模型的训练效率,每次并不是从头开始训练,而是用上一次模型参数来初始化当前模型的参数。
- 模型应用 为了提高服务的响应效率,对每次请求要计算的多个候选APP采用并行评分计算的方式,大大降低响应时间。
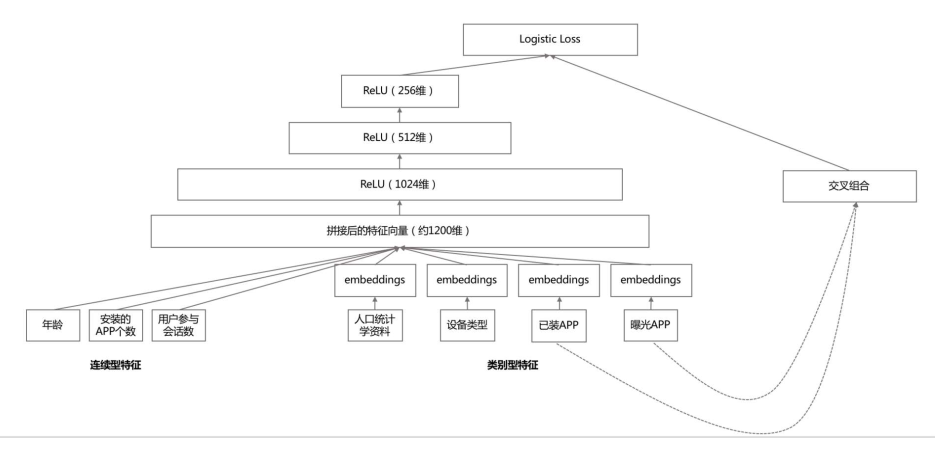
深宽模型结构图
本文是《推荐系统三十六式》的读书笔记,仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture