开源工具
内容分析
基于内容的推荐,主要工作集中在处理文本,或者把数据视为文本去处理,文本分析相关的工作就是将非结构化的文本转化为机构化,主要的工作就三类:
- 主题模型
- 词嵌入
- 文本分类
针对这三类工作的开源工具有:
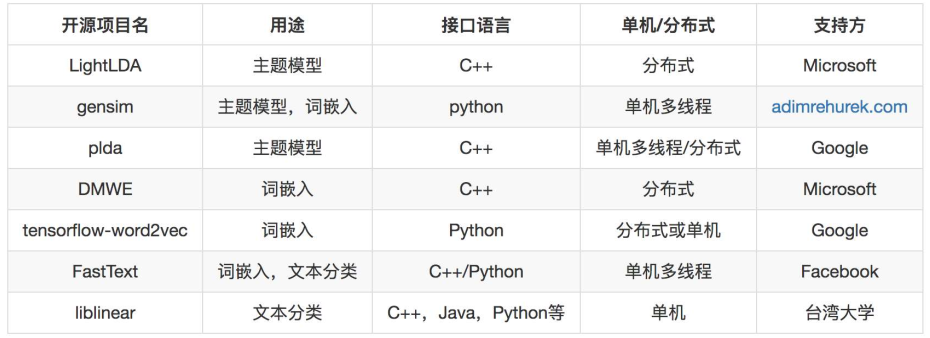
主题模型还有Baidu Familia,词纳入还有FAIR starspace.
如果遇到的数据量还没有那么大,并且分布式维护本身需要专业的人和精力,所以尽量先选择将单机发挥到极致后,遇到瓶颈再考虑分布式。
FastText和Word2Vec的词嵌入是一样的,但是前者还提供分类功能,这个分类非常有优势,效果几乎等同于CNN,但效率却和线性模型一样,在实际项目中久经考验。LightLDA和DMWE都是微软开源的机器学习工具包
协同过滤和矩阵分解
基于用户、基于物品的协同过滤和矩阵分解都依赖对用户物品关系矩阵的使用。经常需要涉及到以下计算:
- KNN相似度计算
- SVD矩阵分解
- SVD++分解
- ALS矩阵分解
- BPR矩阵分解
- 低维稠密向量近邻搜索
基于协同过滤的算法,核心思想是通过计算矩阵的行相似和列相似得到推荐结果。
矩阵分解核心思想是得到用户和物品的隐因子向量,是低维稠密向量,进一步以用户的低维稠密向量在物品的向量中搜索得到近邻结果,作为推荐结果,因此需要专门针对低维稠密向量的近邻搜索。
常见针对协同过滤和矩阵分解开源工具有:
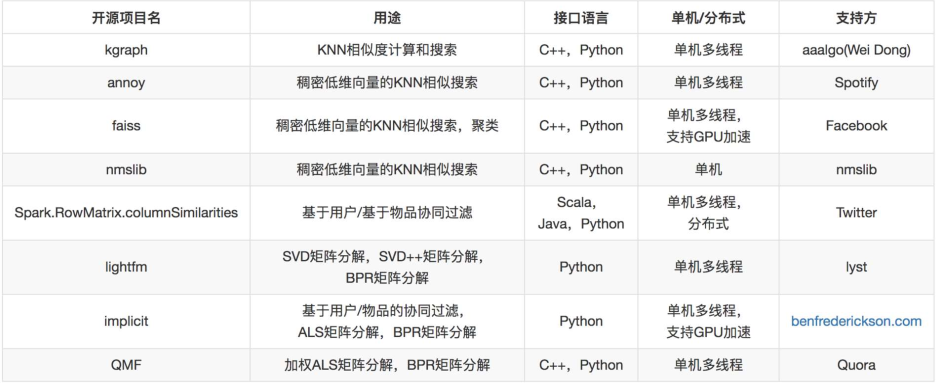
除非数据量达到一定程度如过亿以上,否则慎重选择分布式版本,不划算。
模型融合
模型融合主要有线性模型、梯度提升树模型。
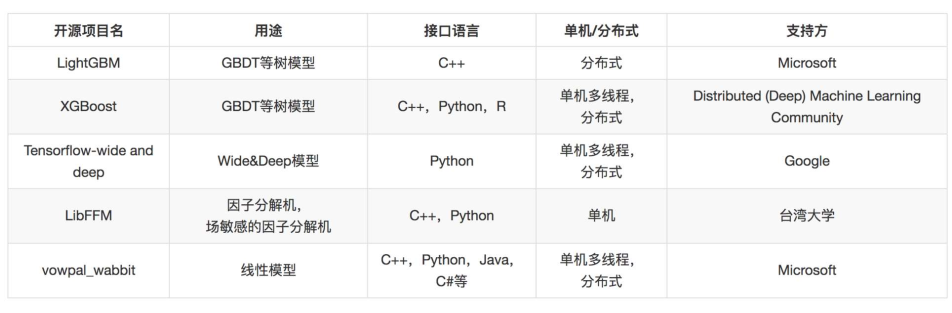
线性模型复杂在模型训练部分,这部分可以离线批量进行,而线上预测部分则比较简单,可以用开源接口实现,也可以自己实现。
完整推荐系统
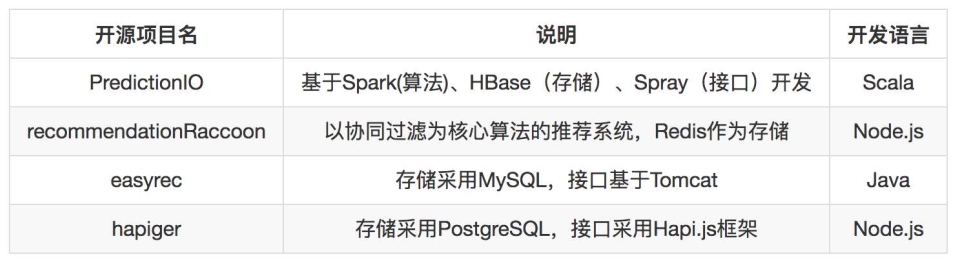
完整推荐系统项目包括推荐算法啊实现、存储、接口,主要有:
总结
完整的推荐系统开源项目,由于其封装过于严密,过于黑盒,因此推荐选择各个模块的开源项目,再组合集成为自己的推荐系统,好处有:
- 单个模块开源项目容易入手,学习成本地,性能好
- 自己组合后更容易诊断问题,不需要的不用开发
- 单个模块的性能和效果更有保证
本文是《推荐系统三十六式》的读书笔记,仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture
{kind=link}