典型信息流架构
整体框架
信息流,也叫”Feed“,行话叫做“Active Stream”, 传统的信息流产品知识简单按照时间排序,而被推荐系统接管后的信息流逐渐成为主流,按照兴趣排序,也叫作“兴趣Feed”。
要实现一个信息流,可以划分为两个子问题:
- 如何实现一个按照时间顺序排序的信息流系统?
- 如何给信息流内容按照兴趣重排序
整体框架如下:
- 日志收集:是排序训练的数据来源,要收集的核心数据就是用户在信息流上产生的行为,用于机器学习更新排序模型
- 内容发布:就是用推或者拉的方式把信息流的内容从源头发布到受众端
- 机器学习:从收集的用户行为日志中训练模型,然后为每一个用户即将收到的信息流内容提供打分
- 信息流服务:为信息流的展示前端提供Rest API
- 监控:这是系统的运维标配,保证系统的安全和稳定等
数据模型
信息流的基本数据有三个:用户(User)、内容(Activity)和关系(Connection)。
Activity
用于表达Activity的元素有相应的规范,叫做Atom,可以参考它并自定义自己的信息流数据模型。
Atom规范定义,一条Activity包含的元素有:Time、Actor、Verb、Object、Target、Title、Summary
Connection
关系就是连接,有强有弱,好友关系、关注关系等社交是较强的连接,还有点赞、收藏、评论、浏览,这些动作都可以认为是用户和另一个对象建立了连接。有了连接,就有信息流的传递和发布。
定义一个连接的元素有下面集中:
- From: 连接的发起方
- To: 被连接方
- Type/Name: 就是Atom模型中的Verb,即连接的类型:关注、加好友、点赞、浏览、评论,等等。
- Affinity: 连接的强弱
连接的发起从From到To,内容的流动从To到From,Connection和Activity是相互加强的,有了Activity,就会产生Connection,就可以Feed给你更多的Activity。
在数据存储上可以选择的工具有:
- Activity存储可以采用MySQL、Redis、Cassandra等
- Connection和User存储可以采用MySQL
内容发布
把内容出现在受众的信息流中的这个过程成为Fan-out。
直观的实现:
- 获取用户所有连接的重点(如好友、关注对象、兴趣标签)
- 获取这些连接终点(关注对象)产生的新内容(Activity)
- 按照某个指标排序后输出
Fan-out-on-load
Twitter早期也是这么做的,这是江湖行话说的”拉模式“,即:信息流是在用户登录或者刷新后实时产生的。
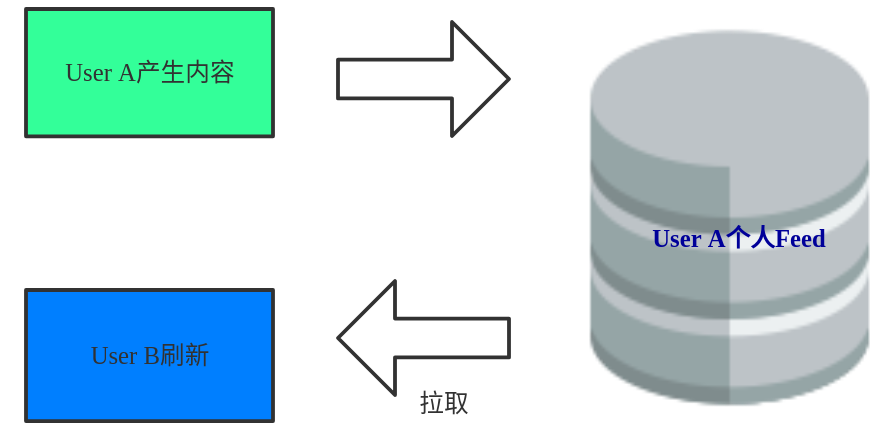
拉模式
拉模式就是当用户访问时,信息流服务才会去相应的发布源拉取内容到自己的Feed区来,这是一个阻塞同步的过程,好处有:
- 实现简单直接:一行SQL语句
- 实时:内容产生了,受众只要刷新就看得见
缺点有:
- 随着连接数的增加,这个操作的复杂度指数级增加
- 内存中要保留每个人产生的内容
- 服务很难做到高可用
Fan-out-on-write
推模式,当一个Actor产生了一条Activity之后,不管受众在不在线,刷没刷新,都会立即将这条内容推送给与Actor建立连接的人。系统会为每一个用户单独开辟一个信息流存储区域,用于接受推送的内容。这样,当用户登录后,系统只需要读取他自己的信息流即可。好处是在用户访问自己的信息流时,几乎没有任何复杂的查询操作,所以服务可用性较高。缺点是:
- 大量的写操作:每一个粉丝都要写一次
- 大量的冗余存储:每一条内容都要存储N份(受众数量)
- 非实时:一条内容产生后,有一定的延迟才会到达受众信息流中
- 无法解决新用户的信息流产生问题
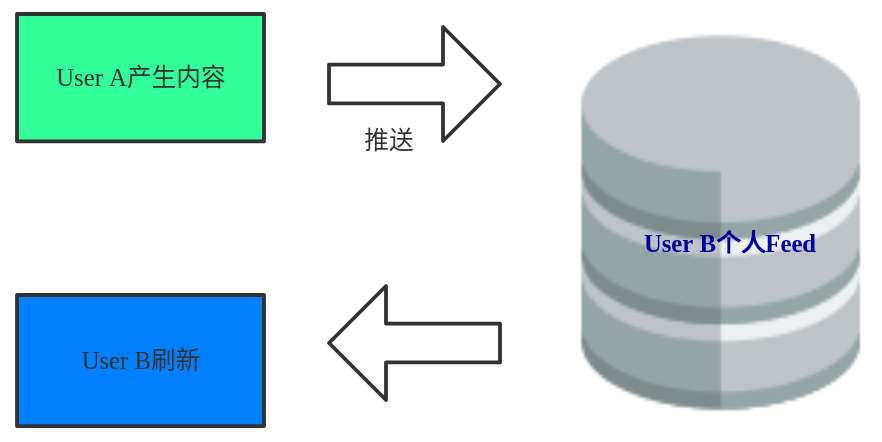
推模式
拉与推模式两者结合
- 对于活跃度高的用户,使用推模式,他们每次刷新不用等太久,内容相对多一些
- 对于活跃度低的用户,使用拉模式,他们登录时才会拉取最新的内容
- 对于热门的内容生产者,缓存其最新的N条内容,用于不同场景下的拉取
也可以根据用户之间的亲密度高低作为概率来选择,亲密度高就优先推送,反之,延迟推送或者不推送。
对于信息流的产生和存储可以选择的工具有:
- 用户信息流的存储可以采用Redistribute等KV数据库,使用UID作为Key
- 信息流推送的任务队列可以采用Celery等成熟框架
信息流排序
信息流排序,要避免陷入没有目标和人工量化的误区。
目前信息流采用机器学习排序,以提升类似互动率,停留时长等指标。基本上可以看成设计一个典型的二分类监督学习的问题了,对一条信息流的内容,在展示给用户之前先预测其获得用户正向互动的概率,概率就可以作为兴趣排序分数输出。
能产生概率输出的二分类算法都可以使用:如贝叶斯、最大熵、逻辑回归等。
大厂数据多可以采用深度学习模型,小厂数据少采用线性模型,对于线性模型,最重要的工作就是特征工程,信息流的特征有三类:
- 用户特征: 包括用户人口统计学属性、用户兴趣标签、活跃程度等
- 内容特征: 一条内容可以根据其属性提取文本、图像、音频等特征,并且可以利用主题模型提取更抽象的特征
- 其他特征: 比如刷新时间、所处上下文信息等
排序模型在实际使用时,通常做成RPC服务,以供发布信息流时调用。
数据管道
信息流是一个数据驱动的系统,既要通过历史数据来寻找最优参数,又要通过新的数据验证排序效果。
从零开始的信息流,没有必要做到在线实时更新排序算法的参数,通常数据管道为:
- 生成训练样本,可离线
- 排序模型训练,可离线
- 模型服务化,实时服务
Facebook VS 今日头条
主要看两者生产者和消费者的关系,Facebook是大家都会生产消费,头条是少数人生产,消费多就用推,生产多就用拉。
Netflix个性化推荐架构
一个好的推荐系统架构应该具有:
- 实时相应请求
- 及时、准确、全面记录用户反馈
- 可以优雅降级
- 快速实验多种策略
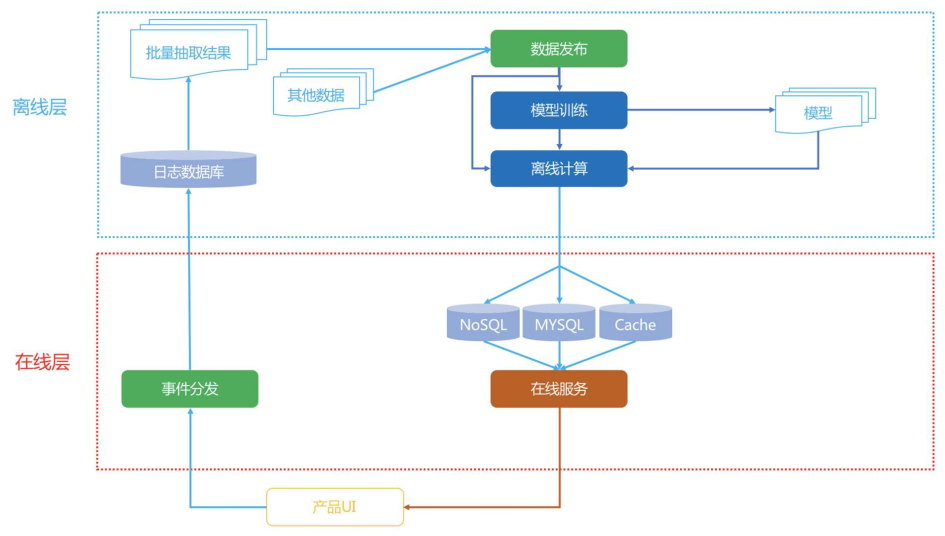
Netflix的系统架构图如下,主要有三层:
- 在线:使用实时数据,要保证实时服务
- 近线:使用实时数据,不保证实时服务
- 离线:不用实时数据,不提供实时服务
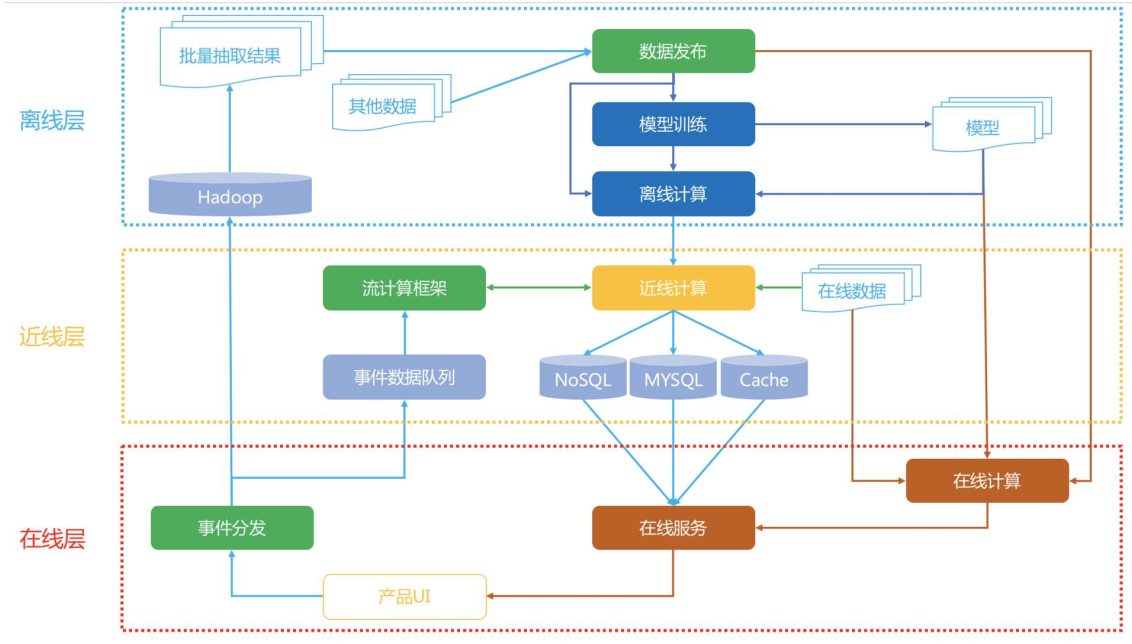
Netflix推荐系统架构图
在线层
在线层需要使用“实时数据,要保证实时服务”,要处理的对象一般是已经预处理后的推荐结果,是少量物品集合。优势有:
- 直接首次接触到大多数最新数据
- 对用户请求时的上下文了如指掌
- 只需计算必须的信息,不需要考虑所有信息
在线层有严格的制约:
- 严格的服务相应时间,不能超时,或者让用户等太久
- 服务要保证可用性,稳定性
- 传输的数据有限
通常在线层的展现形式就是Rest API,后端则通常是RPC服务内部互相调用,以用户ID、场景信息去请求,通常就在ms相应时间类返回JSON形式的推荐结果。
如果发生意外,比如这个物品ID没有相关的物品,需要降级处理,就是不能达到最好的效果,但是不能低于最低要求,即不能开天窗,必须返回东西,常见做法是返回排行榜的物品。这就是服务的可用性。
离线层
离线层是批量、周期性地置信一些计算任务,其特点是“不同实时数据,不提供实时服务”,示意图如下:
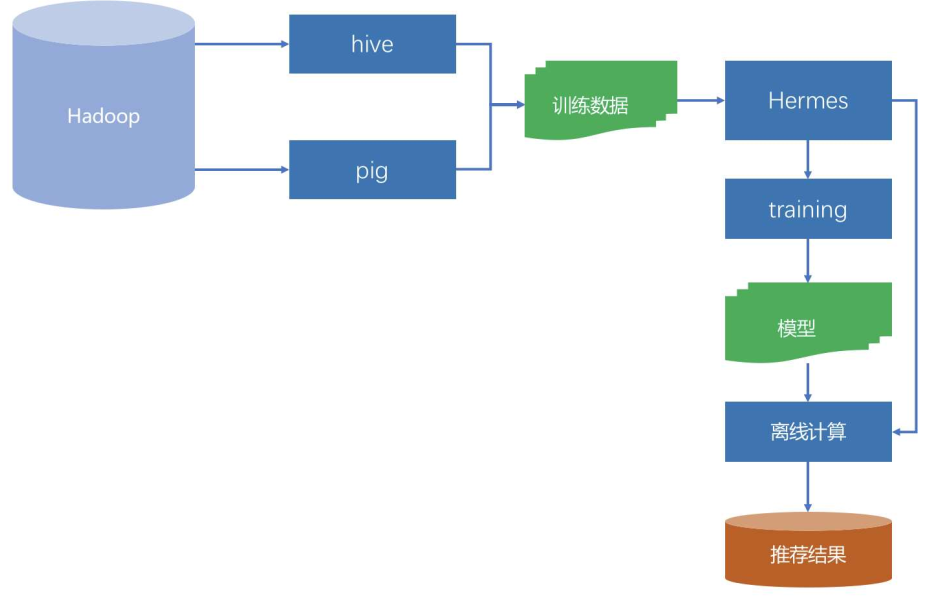
Netflix推荐系统架构图
离线阶段主要面对的数据源是Hadoop,实质上是HDFS,收集到的所有日志都存在这里,是一个全量的数据中心。
数据源多时,需要专门的工具统一管理,要求:
- 数据准备好之后及时通知相关方,也就是要有订阅发布的模式
- 能够满足下游不同的存储系统
- 完整的监控体系,并且监控过程对于数据使用方是透明的
在Netflix内部,使用Hermes作为管理任务的工具,类似Kafka。
离线阶段的任务主要是两类:模型训练和推荐结果计算,好处有:
- 可处理最大的数据量
- 可进行批量处理和计算
- 不用有响应时间等要求
坏处有:
- 无法及时相应前端需求
- 面对的数据教静态,无法及时反应用户的兴趣变化
大多数推荐算法,实际上都是在离线阶段产生推荐结果的,离线阶段的推荐计算和模型训练,如果要用分布式框架,通常可以选择Spark等。
近线层
近线层需要“使用实时数据,不保证实时服务”,也叫作准实时层,就是接近实时,但不是真的实时。
近线计算任务一个核心组件是流计算,因为它要处理实时数据流。常用流计算框架有Storm,Spark Streaming,FLink等。Netflix采用的内部流计算框架Manhattan。
简化版架构
新的推荐系统建议简化架构,如下图:
Netflix推荐系统架构图
关键简化有两点:
- 完全舍弃掉近线层
- 避免使用分布式系统
对于Bandit算法,需要根据场景反馈调试模型的参数值,适合还没有任何模型效果数据的冷启动,当候选臂的数量不大或者结合上下文和协同过滤能降低臂的个数时,可以用到在线层中,纯Bandit适合在离线部分,保证长尾物品的曝光。
三层综合对比
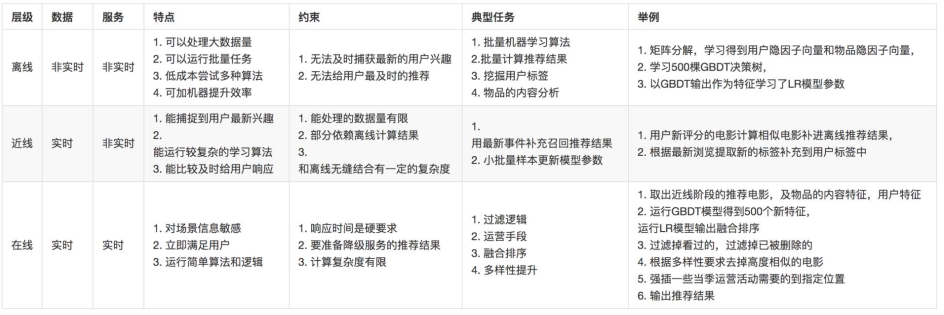
推荐系统架构的三层对比
总览推荐架构和搜索、广告的关系
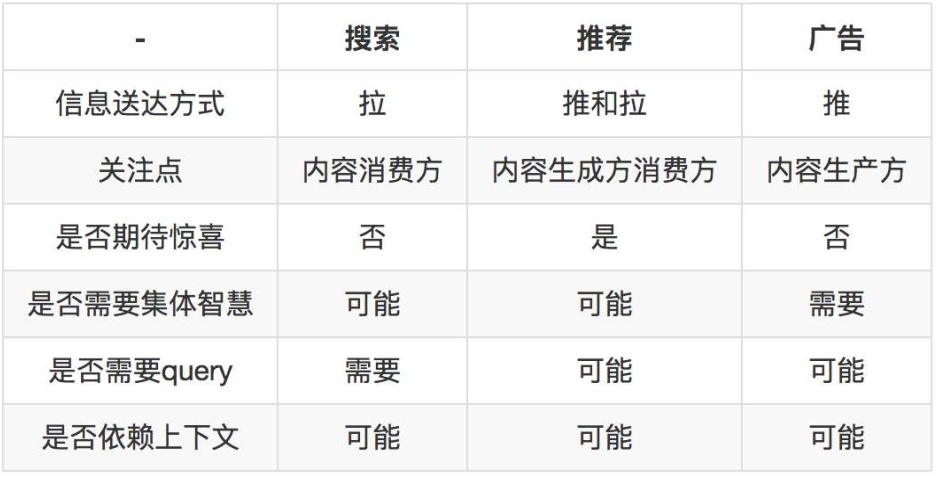
搜索,推荐和广告本质上都是在解决信息过载的问题,各自解决的手段、目标不相同,各自诞生在产品生命周期不同阶段,以至于系统实现也不尽相同。搜索和推荐都是为人找信息,而广告是为信息找人。
Netflix推荐系统架构图
- 搜索更关注消费者,搜索要解决的是精确快速找到想要的结果,最重要的目标是降低延迟和提高相关性。搜索引擎是一个效率工具,希望用户找到信息越快越好,而不是希望用户沉迷搜索引擎中,往往针对一个用户发起的请求
- 推荐系统通常的目标不是帮助用户找到相关内容,而是希望用户消费内容,消费越多越好。好的推荐系统应该是一个时间杀手,让用户走进去就不想出来。可以针对单个用户或者用户群体进行推荐
- 广告背后是纯粹的商业目标,其关注的是商业利益最大化,精准和相关都不是终极目的,只是其中的一个手段
搜索、推荐和广告三者本质上都是在匹配,匹配用户的情绪和需求(看成Context),但是匹配的目标,条件和策略不尽相同,示意图如下:
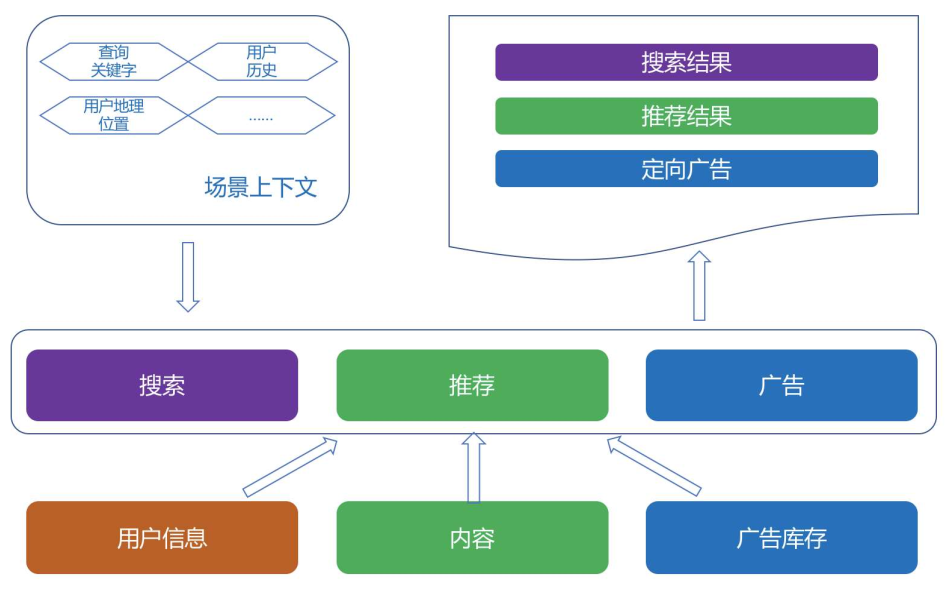
再进一步可以抽象为三步:过滤候选、排序候选、个性化输出。
过滤候选
三者都需要过滤候选,而过滤候选就离不开建立索引。可以使用ElasticSearch搭建搜索引擎。
排序候选
对于三者来说,主要的区别在于排序的目标和约束。
- 搜索:目标是高相关性,BM25代表的传统模型或者Learn to Rank为代表的机器学习排序目标都是希望把用户每次在搜索上花费的时间是不是更少(而不是更多)来衡量搜索的结果
- 推荐:排序比较复杂,根据推荐系统不同的产品形式、产品目标,排序策略也不同
- 广告:更多的是从经济学角度去看,需要考虑诸多因素,如商业因素、平台方的要求等,是一个纯动态的博弈
个性化输出
推荐系统最看中个性化输出,个性化只是推荐系统的衡量指标之一,个性化的前提也一定是信息够丰富和垂直才行。
三者协同
盲目的搜索可以借助推荐产生结果,如“一个人的夜晚听什么歌”,推荐总体上滞后于用户的及时需求,因此需要搜索引擎来与之配合。
对用户的信息需求满足,搜索和推荐离真正得到满足之间总是有一定的鸿沟,要么是信息不足,要么是信息过载,这些鸿沟都可以利用经济手段进行调配,这就是广告系统。
本文是《推荐系统三十六式》的读书笔记,仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture